


今年以来,随着生成式AI人工智能的迅猛发展,人工智能的狂飙模式已经被彻底被打开。如今想要玩转人工智能,必然需要大规模计算机集群来支撑。目前来看,单个的GPU性能确实也都上去了,但是对于一些大规模的模型计算来说,还是存在很大的瓶颈。那就得看GPU之间的数据传输速度了。
目前的GPU互联方式主要有两种,一种是PCIe,另一种是NVlink。接下来我们邀请猿界算力高级工程师来给大家分析他们两者架构之间的区别。
PCIe和NVLINK是什么?
PCIe和NVLink都是用于连接计算机内部组件的两种不同技术接口。
1. PCIe(Peripheral Component Interconnect Express):它是一种计算机总线标准,用于在计算机内部连接各种设备和组件(例如显卡、存储设备、扩展卡等)。PCIe接口以串行方式传输数据,具有较高的通信带宽,适用于连接各种设备。然而,由于其基于总线结构,同时连接多个设备时可能会受到带宽的限制。
2. NVLink(Nvidia Link):它是由NVIDIA开发的一种高速、低延迟的专有连接技术,主要用于连接NVIDIA图形处理器(GPU)。NVLink提供了具有很高带宽和低延迟的直接GPU间通信能力,多个GPU通过英伟达SXM封装技术封装在一起,使得多个GPU可以在更紧密和高效的方式下协同工作。相比于PCIe,NVLink在支持GPU之间的数据传输和协作方面提供了更好的性能和效率。
 英伟达A800的PCIe和NVLINK之间的区别
英伟达A800的PCIe和NVLINK之间的区别
简而言之,PCIe是一种通用的计算机总线标准,适用于连接各种设备和组件,而NVLink是专为GPU间通信而设计的技术,提供了更快的连接和更高的数据传输速度。
那么他们之间分别有哪些优劣势?PCIe和NVLink在连接计算机内部组件方面具有不同的优缺点。
PCIe的优点包括:
1. 通用性:PCIe是一种通用接口标准,适用于连接各种设备和组件,包括显卡、存储设备、网络卡等。从兼容性的角度来看,PCIe接口更广泛支持不同品牌和型号的设备。
2. 可扩展性:PCIe接口支持多个设备同时连接,并通过总线架构进行数据传输。这使得用户可以在计算机中连接多个设备,并且可以在需要时轻松添加或更改这些设备。
然而,PCIe也存在一些缺点:
1. 带宽限制:由于PCIe接口基于总线架构,多个设备共享总线的带宽,可能会导致带宽限制。特别是在连接高性能计算设备(如多块显卡)时,带宽限制可能会对数据传输速度和性能产生一定影响。
2. 延迟增加:由于数据在总线上进行传输,因此PCIe接口可能会引入一定的传输延迟。对于需要低延迟的场景(如大规模集群或高性能计算),PCIe可能不是最佳选择。

相比之下,NVLink具有以下优点:
1. 高带宽和低延迟:NVLink提供了更高速的连接和数据传输,可显著提高GPU之间的数据传输速度和性能。这对于需要高速数据交换和低延迟通信的应用场景非常重要,例如深度学习、高性能计算等。
2. 协同计算:NVLink支持直接GPU之间的数据共享和通信,可以实现更高效的协同计算。多个GPU可以更紧密地合作处理任务,提供更大的计算能力和吞吐量。
然而,NVLink也存在一些限制:
1. 专有性:NVLink是由NVIDIA开发的专有连接技术,只适用于连接NVIDIA的GPU。这限制了NVLink的通用性和与其他品牌设备的兼容性。
2. 可扩展性:与PCIe相比,NVLink的连接数量和扩展能力有限。由于专为GPU设计,连接多个GPU时的扩展能力可能受到限制。
NVLINK明显的优势就是高带宽和低延迟,我们先来看看他们的速度对比。传统的PCIe5.0x16规格下互联速度为128GB每秒,而第四代NVlink的规格下,直接达到900GB每秒,也就是PCIe的7倍多(参考下图)。
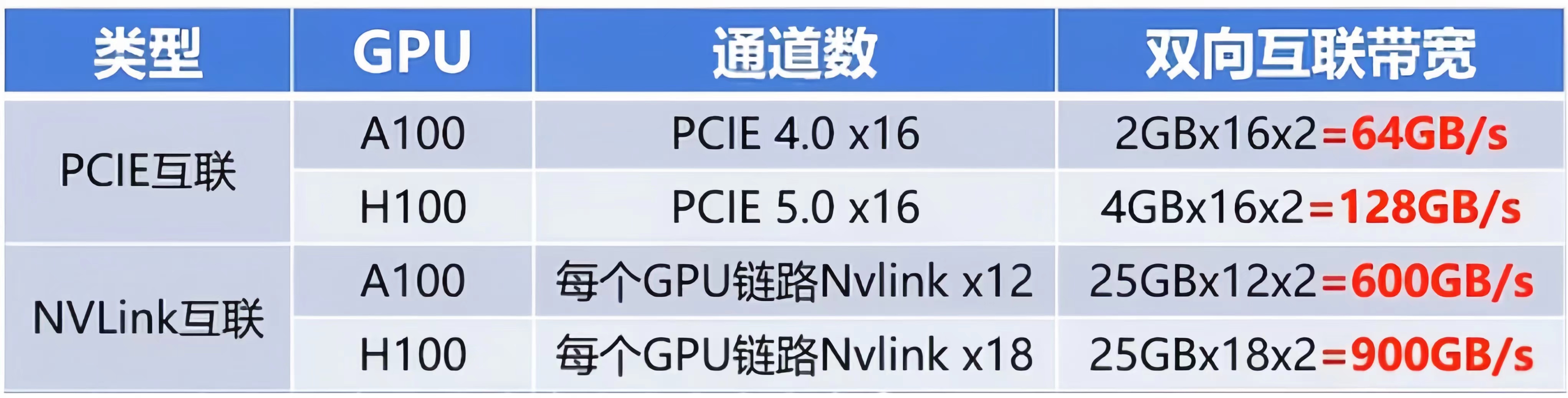 两者通信速度方面的区别
两者通信速度方面的区别
另外,为了更直观地区别他们之间的数据传输差距,从下图可以看出,传统的PCIe数据交互方式是CPU与GPU之间的数据交互,图中可以看出带宽非常的细窄,而NVlink的交互方式直接绕开了CPU,通过GPU和GPU直连的方式进行数据交互,传输的通道非常地宽敞。如果对于注重GPU之间数据通信的大规模训练来说,NVlink无疑是最佳性能选择,这也就是目前NVLINK在人工智能领域大行其道的主要原因。虽然NVLINK的价格目前不菲,但是综合时间成本和效率对比的话,它的训练效率和性价比还是比PCIe高出很多的。
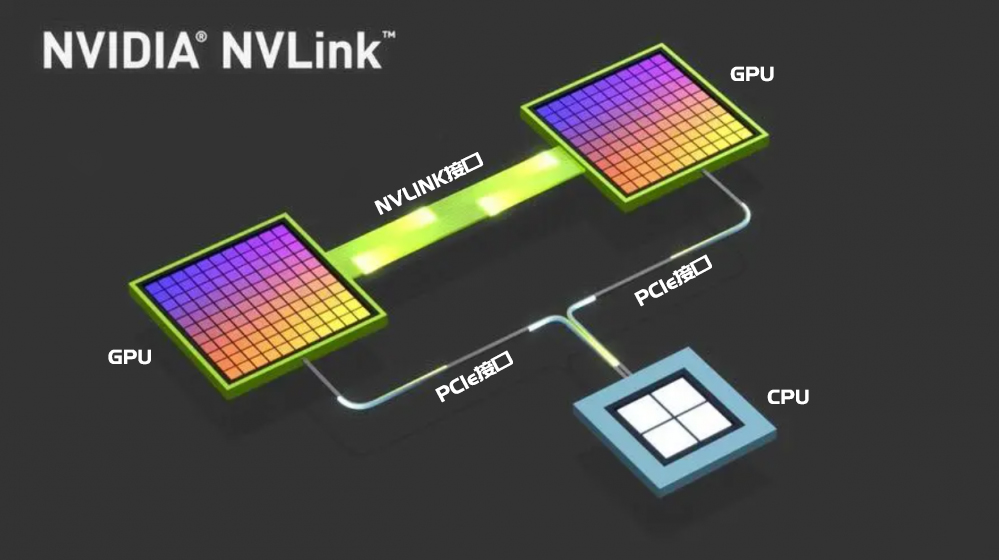 CPU之间以及GPU和CPU之间的通信接口的区别
CPU之间以及GPU和CPU之间的通信接口的区别
因此,NVLink在人工智能领域的应用前景广阔,特别是在大规模模型计算和高性能计算方面具有显著优势。虽然目前其价格较高,但随着技术的成熟和应用的推广,未来有望成为人工智能领域的主流选择。
猿界算力-GPU服务器租赁服务商
(点击下图进入算力租赁介绍页面)

