


AI服务器的数据通信涉及到3个部分:服务器内部通信、AI集群内服务器之间通信,以及跨集群的广域通信。
服务器内部GPU之间的高速通信主要采用NVLink,当然,英伟达也在利用NVLink来构建集群SuperPOD,但其支持的GPU规模相对有限,主要应用于小规模跨服务器节点间的数据传输。大型AI集群主要还是依靠RDMA网络,也就是采用RoCE或InfiniBand。
本文以典型英伟达A100服务器为例,详细说明一下各组件之间的联网架构。A100服务器内部的网络连接方式如下图所示:
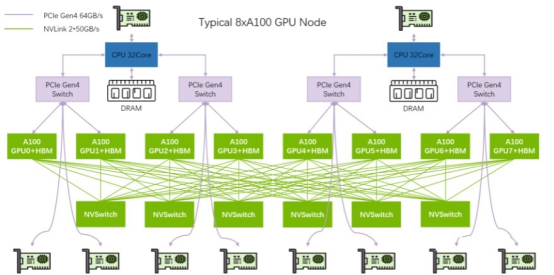
A100服务器的主要模块包括:2个CPU、2张InfiniBand存储网卡(BF3 DPU)、4个PCIe Gen4 Switch芯片、6个NVSwitch芯片、8个GPU(A100)、8个InfiniBand网卡。8个GPU通过6个NVSwitch芯片全网状连接(Full-mesh)。
1、主机内部GPU之间,采用NVLink:A100双向带宽为12*50GB/s=600GB/s;A800是阉割版,双向带宽变为8*50GB/s=400GB/s2、主机内部GPU与网卡之间:GPU <--> PCIe Switch <--> NIC,理论上单向32GB/s3、跨主机GPU之间:
通过InfiniBand网卡收发数据。如下图所示:
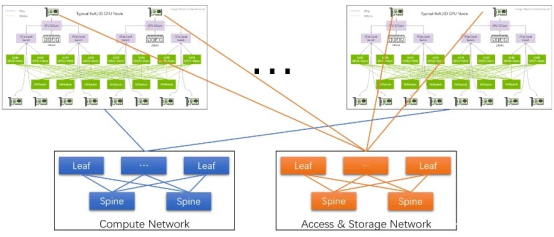
不管是计算网络还是存储网络,都需要RDMA才能满足AI所需的高性能。网络采用Spine-Leaf架构:8块GPU通过InfiniBand网卡(HDR,200Gbps)直连到Leaf交换机,Leaf交换机通过Full-mesh连接到Spine交换机,形成跨主机GPU计算网络。
A100中InfiniBand网卡采用HDR,是因为HDR单向200Gbps(即25GB/s)已接近PCIe gen4单向32GB/s的理论速度。就算高配NDR(单向400Gbps,即50GB/s)作用也不大。
结论:
InfiniBand作为一种原生的RDMA网络,在无拥塞和低延迟环境下表现突出,但其架构相对封闭,成本较高(同等带宽下,InfiniBand性能比RoCE好20%以上,价格却要贵一倍),因此,InfiniBand主要适用于中小规模集群场景。
RoCE则凭借其成熟以太网生态、低组网成本以及快速技术迭代,更适用于中大型训练集群场景。例如,当前公有云服务商卖的8卡GPU主机基本都是RoCE网络。
