


NVIDIA H100 GPU 是英伟达于2022年3月GTC技术大会上发布的第九代数据中心级GPU,基于全新 Hopper架构,取代了前代Ampere架构(A100)。这一架构以计算机科学先驱Grace Hopper命名,旨在解决大模型训练、实时推理和高性能计算(HPC)的算力瓶颈。 Hopper架构的诞生标志着GPU技术从通用计算向专用加速的深度演进。此前,A100(Ampere架构,2020年发布)凭借7nm工艺、第三代Tensor Core和HBM2e显存,成为AI与科学计算的标杆。然而,随着千亿参数大模型(如GPT-4)的崛起,传统架构在算力密度、互联带宽和能效上面临挑战。H100通过TSMC 4N定制工艺、800亿晶体管集成(较A100提升48%)和六项关键技术突破,实现了代际性能跃迁。
核心技术创新与硬件特性
架构设计:从Ampere到Hopper的跨越
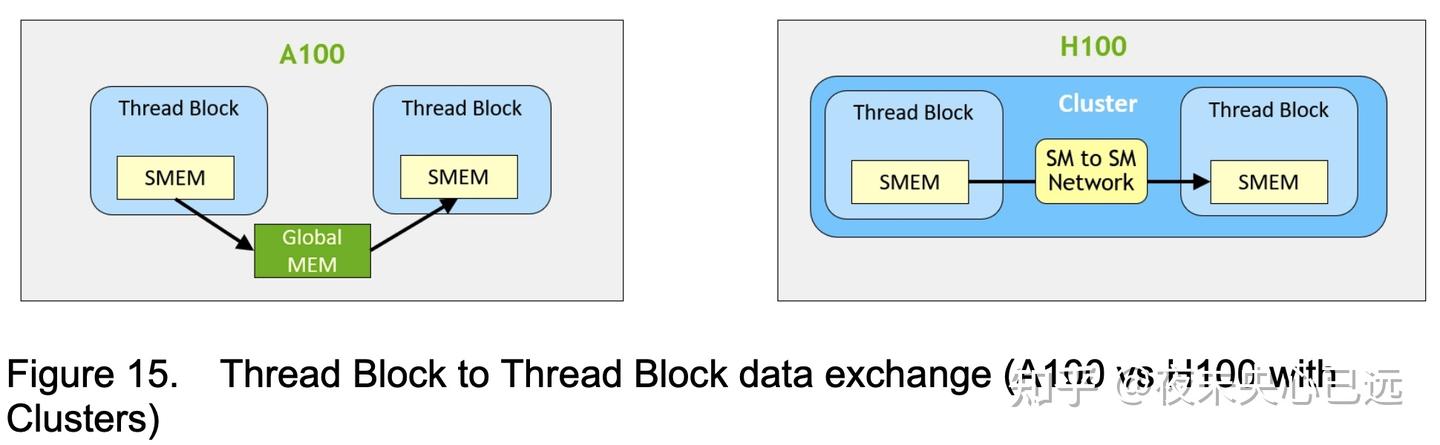
Hopper架构的核心改进在于对并行计算范式的重构,H100是首款真正异步的GPU,其扩展了A100的全局到共享内存的异步传输功能,覆盖所有地址空间,并新增对张量内存访问模式的支持。它允许应用程序构建端到端的异步流水线,实现数据进出芯片的传输与计算的完全重叠和隐藏。。A100的Ampere架构以通用计算为主,而H100通过线程块集群(Thread Block Cluster)和异步事务屏障(Asynchronous Transaction Barrier),首次实现了跨流式多处理器(SM)的协同调度与数据共享。这种设计使多个线程块能高效驱动Tensor内存加速器(TMA)和Tensor Core,显著提升计算管线利用率。
计算单元:第四代Tensor Core与FP8革命
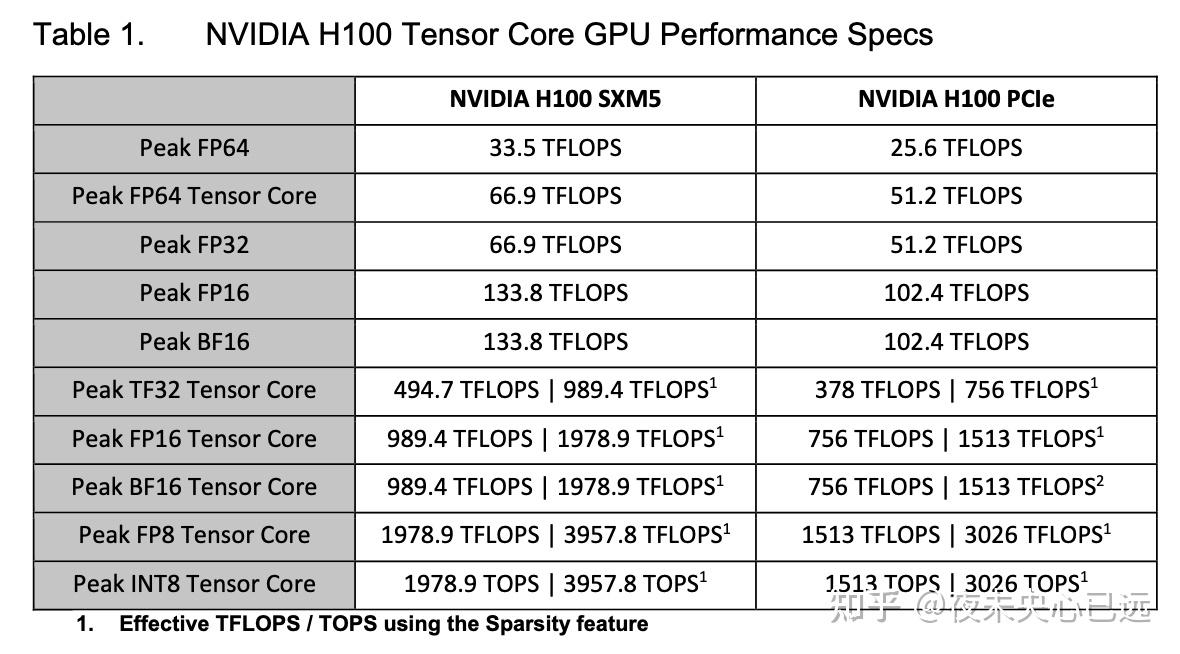
H100的第四代Tensor Core支持FP8精度,其稀疏计算能力可达4,000 TFLOPS,较A100的FP16算力提升6倍。FP8的引入不仅降低了显存占用(减少70%),还通过Transformer引擎动态切换FP8/FP16精度,自动处理权重缩放与精度补偿。实测显示,H100在训练1750亿参数的GPT-3模型时,速度较A100提升9倍,推理延迟缩短至次秒级。 互连与显存:NVLink 4.0与HBM3突破
H100搭载的第四代NVLink提供900 GB/s900 GB/s单卡互联带宽,结合NVSwitch技术可扩展至256卡集群,全对全带宽达57.6 TB/s,是PCIe Gen5的7倍。显存方面,HBM3技术将带宽提升至3.35 TB/s3.35 TB/s(较A100的HBM2e提升68%),配合50MB L2缓存,可承载全球互联网级别的数据吞吐。
安全与能效:机密计算与能效优化
H100首次引入机密计算功能,通过硬件隔离保护敏感数据(如医疗基因组学),并支持第二代多实例GPU(MIG),将单卡划分为7个独立实例,为云服务提供安全的多租户环境。尽管H100的典型功耗达700W(较A100提升75%),但其每瓦FP16性能提升至2.83 TFLOPS/W,三年总拥有成本(TCO)降低28%。 图6展示了完整版的GH100 GPU,该芯片包含144个流式多处理器(SM)。而实际量产的H100 GPU根据形态不同分为两个版本:采用SXM5接口封装的版本包含132个SM,PCIe版本则缩减至114个SM。需要特别说明的是,H100 GPU的核心设计目标是为数据中心和边缘计算场景的人工智能(AI)、高性能计算(HPC)及数据分析任务提供加速支持,其硬件架构并未针对传统图形渲染进行优化。在SXM5和PCIe版本的H100 GPU中,仅有2个纹理处理集群(TPC)具备图形处理能力,即支持运行顶点着色器(Vertex Shader)、几何着色器(Geometry Shader)和像素着色器(Pixel Shader)——这种设计意味着H100虽然保留了基础的图形管线,但本质上仍是面向计算密集型负载的专用加速器。

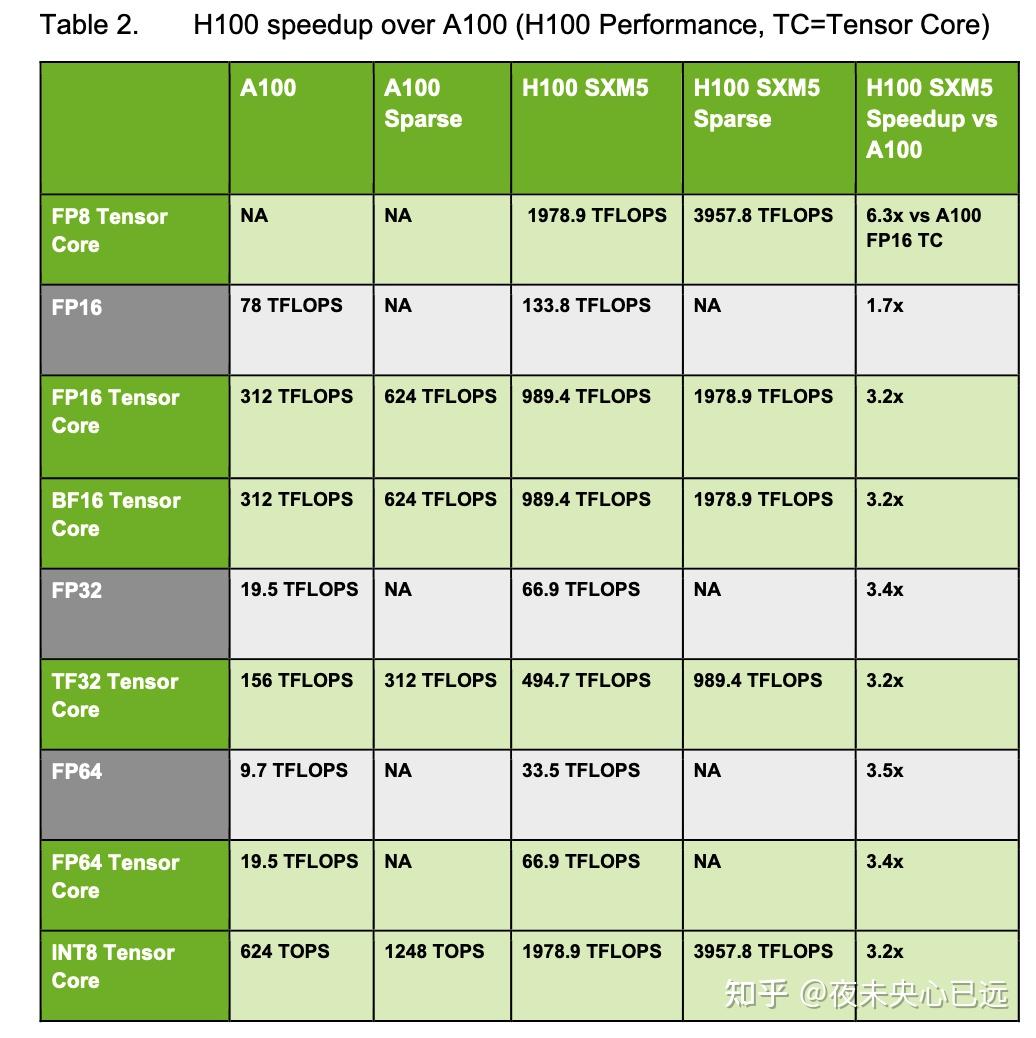
基于NVIDIA A100 Tensor Core GPU的流式多处理器(SM)架构,H100的SM通过引入FP8精度,在相同时钟频率下实现了单SM浮点计算能力的四倍提升,同时在原有Tensor Core支持的FP32/FP64数据类型上实现双倍算力增长。 全新Transformer引擎与Hopper架构的FP8张量核心结合,使得H100在大型语言模型训练中较前代A100提速高达9倍,推理速度更提升30倍。Hopper新增的DPX指令集可将基因学和蛋白质测序领域的史密斯-沃特曼算法处理速度加速7倍。第四代张量核心、张量内存加速器以及SM架构的整体优化,使得H100在多数高性能计算(HPC)和人工智能场景下实现最高3倍的性能飞跃。
算力值:
SM架构:

H100 SXM版本与PCIE版本
| 参数 | H100 SXM5 | H100 PCIe |
|---|---|---|
| SM数量 | 132个 | 114个(减少14%) |
| Tensor Core数量 | 528个 | 456个(减少14%) |
| FP16稀疏算力 | 1.98 PetaFLOPS | 1.51 PetaFLOPS |
| FP8稀疏算力 | 3.96 PetaFLOPS | 3.03 PetaFLOPS |
| 显存带宽 | 3 TB/s(HBM3) | 2 TB/s(HBM2e) |
关键差异:SXM5通过更高的SM数量和HBM3显存,提供约30%的绝对性能优势,尤其适合密集计算负载。
场景影响:SXM5在多GPU训练(如LLM)中延迟更低,PCIe版本更适合单卡推理或小规模集群。
互连技术与扩展性
1. NVLink互连
(1) SXM5:集成18个第四代NVLink链路,总带宽900 GB/s,支持8卡全互联(通过NVSwitch)。
(2)PCIe:可选NVLink桥接(2卡互联),带宽**600 GB/s**,但需占用物理空间且扩展性受限。
2. PCIe Gen5接口
(1)SXM5:仅用于CPU通信,带宽64 GB/s(双向)。
(2)PCIe:主通信接口,带宽128 GB/s(双向),支持原子操作优化CPU-GPU同步。
散热与功耗
1. TDP功耗
(1) SXM5:700W,需液冷或定制风冷(如DGX系统)。
(2)PCIe:350W,兼容标准服务器散热方案。
2. 能效比:SXM5在满载时性能/瓦特更高,PCIe更适合能效敏感场景。
SM Architecture
Fourth-generation Tensor Cores
作为专为矩阵乘加运算(MMA)设计的高性能计算单元,张量核心(Tensor Core)已成为AI训练、推理及科学计算的核心加速引擎。其独特架构通过并行化矩阵操作,显著超越传统浮点(FP)、整数(INT)及融合乘加(FMA)单元的吞吐量与能效表现。 自2017年NVIDIA Tesla® V100首次引入张量核心以来,每一代架构迭代均带来突破性升级。H100搭载的第四代张量核心实现三大创新:
算力密度倍增:在相同时钟频率下,H100每个流式多处理器(SM)的密集矩阵计算吞吐量较A100翻倍,稀疏矩阵运算效率提升更高。若叠加H100更高的GPU Boost频率(较A100提升约30%),实际性能增益可达2.6倍。
全数据类型支持:覆盖FP8、FP16、BF16、TF32、FP64及INT8精度,满足从大模型训练到边缘推理的多元需求。其中FP8与TF32(张量浮点32位)专为Transformer类模型优化,可减少70%显存占用并提升3倍计算吞吐。
能效优化:通过数据压缩与片上缓存优化,操作数传输功耗降低30%,这对700W TDP的H100实现能效平衡至关重要。
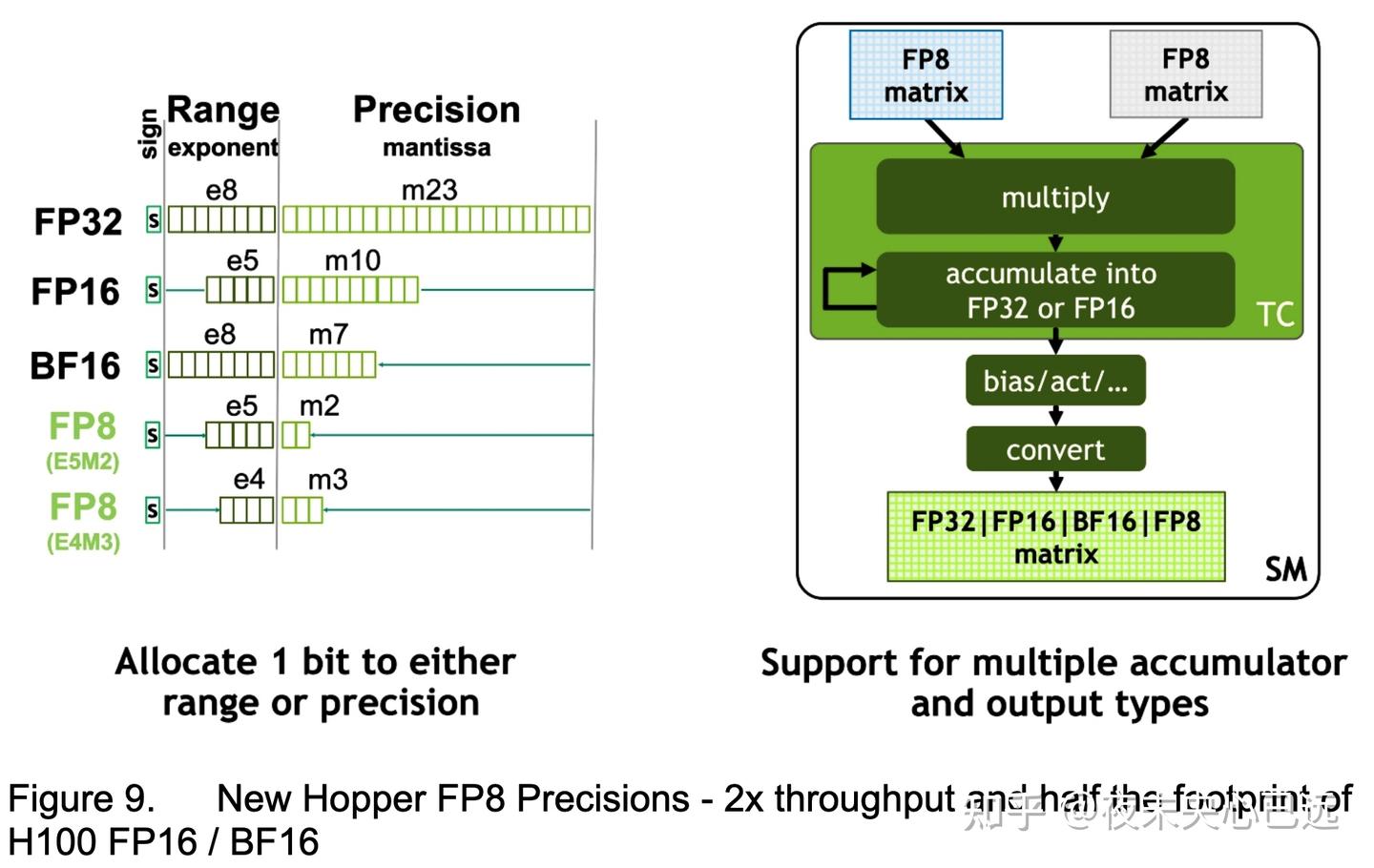
Hopper FP8 Data Format
H100 GPU新增FP8张量核心(Tensor Cores),专为提升AI训练和推理性能设计。如图9所示,FP8张量核心支持以下特性: 混合精度计算:支持FP32和FP16累加器,兼容多种精度需求。 两种新型FP8输入格式:
E4M3:包含4个指数位、3个尾数位和1个符号位,适用于需要更高精度但动态范围较小的计算场景。
E5M2:包含5个指数位、2个尾数位和1个符号位,提供更宽的动态范围,但精度略低。
FP8的优势:
存储效率翻倍:相比FP16或BF16,FP8将数据存储需求减半,显存占用显著降低。
吞吐量翻倍:相同硬件规模下,FP8的理论计算吞吐量是FP16或BF16的两倍。
Transformer引擎的优化(详见后续章节):
H100通过创新的Transformer引擎,动态结合FP8与FP16精度:
内存优化:在矩阵乘法和注意力机制中智能选择FP8存储中间结果,减少内存带宽压力。
性能提升:通过混合精度计算加速训练与推理,同时借助无损格式转换技术(如缩放因子补偿),确保大语言模型等高精度场景的准确性。
H100 GPU Hierarchy and Asynchrony Improvements
在并行程序设计中,数据局部性与异步执行是提升性能的关键。
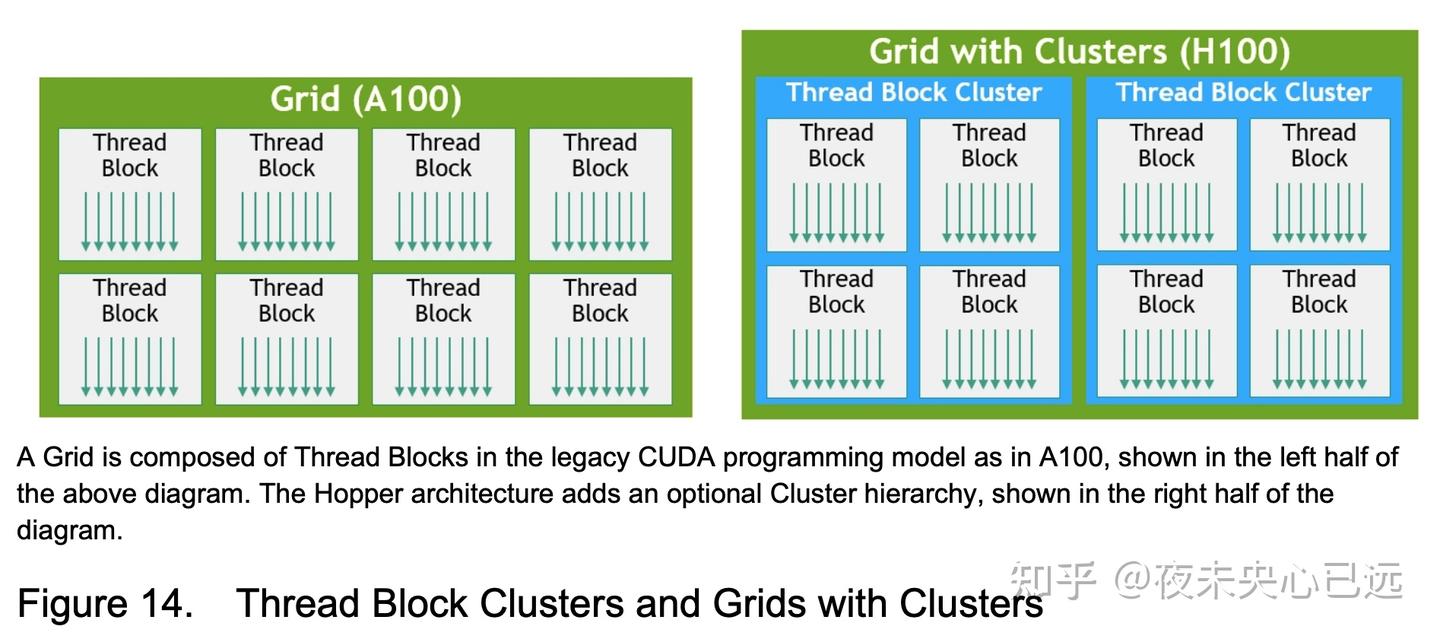
数据局部性要求将程序数据尽可能移至执行单元(如GPU的流式多处理器SM)附近,从而利用低延迟、高带宽的本地数据访问优势。例如,将频繁使用的数据缓存至SM的共享内存(Shared Memory)或寄存器,可减少全局显存访问的开销。 异步执行则侧重于发现独立任务,使其与内存传输或其他计算过程重叠执行。例如,在GPU进行核函数计算的同时,通过异步内存拷贝引擎(如CUDA Stream)预加载下一批数据,从而隐藏数据传输延迟。其核心目标是维持GPU所有计算单元的满载运行,避免因空闲导致的性能损失。 Hopper架构在编程层级中新增的线程块集群(Thread Block Cluster),这一设计首次支持跨多个SM的线程块协作,将数据局部性优势扩展至单个SM线程块之上的更大规模。同时,Hopper引入的异步事务屏障(Asynchronous Transaction Barrier)与张量内存加速器(Tensor Memory Accelerator),可显著降低同步开销并提升异步执行效率,例如允许跨集群的线程与加速器单元协同处理数据依赖关系,同时保持计算管线的持续运转。
Thread Block Cluster
自CUDA编程模型诞生以来,其核心设计一直围绕网格(Grid)和线程块(Thread Block)的层级结构展开。传统模型(三层模型)中,一个线程块包含多个线程,这些线程在单个SM上并发执行,通过快速屏障同步和共享内存实现数据交换。然而,随着现代GPU的SM数量突破100个(例如H100拥有144个SM),且计算任务复杂度激增,仅依赖线程块作为局部性单元已无法充分释放硬件性能潜力。 H100引入的线程块集群架构,将编程模型的局部性控制粒度从单个SM内的线程块扩展至跨多个SM的协作单元。这一设计在CUDA编程层级中新增了第四级结构(四层模型):
线程(Thread) → 线程块(Thread Block) → 线程块集群(Thread Block Cluster) → 网格(Grid)
核心特性:
1. 跨SM协同调度 Cluster由一组线程块构成,这些线程块保证被并发调度到同一图形处理集群(GPC)内的多个SM上。GPC是硬件层级的物理单元,其内部的SM在芯片布局上紧密相邻,确保低延迟通信。
2. 硬件加速屏障与内存协作 Cluster内支持硬件加速的屏障同步(较传统软件屏障延迟降低90%),并新增跨SM内存协作能力。例如,通过专用SM间网络(SM-to-SM Network),集群内的线程可直接访问其他SM的共享内存,实现数据高效共享。
3. 灵活编程接口 开发者可在内核启动时通过CUDA Cooperative Groups API将网格中的线程块动态分组为Cluster(如图14所示)。这种灵活性允许针对不同算法(如动态规划、多阶段模型推理)定制Cluster规模,例如将8个线程块绑定为一个Cluster以处理数据依赖密集型任务。
| 对比维度 | 三层模型 | 四层模型(Compute Capability 9.0+) |
|---|---|---|
| 调度单元 | 线程块(Block)由单个 SM 独立执行,无法跨 SM 协作。 | 线程块集群(Cluster)由多个块组成,集群内的块保证在同一 GPC(GPU Processing Cluster) 的多个 SM 上协同调度。 |
| 资源分配范围 | 每个 SM 单独管理其分配的线程块资源(寄存器、共享内存)。 | Cluster内线程块共享 GPC 级资源(如 L2 缓存),但各块独占所在 SM 的寄存器、共享内存。 |
| 执行粒度与协作范围 | 块内线程通过共享内存和 __syncthreads() 协作,协作范围限于单 SM。 | Cluster内跨 SM 的块可通过 Cluster Group API 同步(如 cluster.sync()),支持Cluster级协作(如共享全局内存数据)。 |
| 延迟与通信效率 | 跨块通信需通过全局内存,延迟较高(受制于显存带宽)。 | Cluster内块可通过分布式共享内存(DSMEM技术,H100 引入),无需依赖共享内存,降低跨 SM 通信延迟。 |
| 编程模型 | 仅需定义网格(Grid)和块(Block)维度,无显式集群声明。 | 需显式声明Cluster维度(如 __cluster_dims__(X,Y,Z))或通过 cudaLaunchKernelEx 动态配置。 |
| 硬件资源利用率 | 单 SM 的线程块数量受限于其资源(如共享内存、寄存器)。 | Cluster可跨多个 SM 分配块,通过资源复用和负载均衡提升 GPC 内整体资源利用率。 |
| 适用场景 | 简单并行任务(如独立矩阵运算)、无需跨块协作的场景。 | 复杂协作任务(如跨块数据交换、大规模图遍历)、需低延迟同步或共享中间结果的算法。 |
| 性能优化潜力 | 依赖块内线程的局部性优化,受限于单 SM 的并行能力。 | 通过Cluster级数据局部性(如 L2 缓存重用)和跨 SM 并行执行,显著提升吞吐量。 |
| 硬件支持 | 所有支持 CUDA 的 GPU。 | 仅 Compute Capability 9.0+ 的 GPU(如 Hopper 架构的 H100)。 |
性能提升与应用场景
1. 大规模并行计算:在基因组序列比对(Smith-Waterman算法)中,集群架构可将跨SM数据交换延迟从微秒级降至纳秒级,加速比达7倍。
2. AI模型训练:Transformer类模型的多头注意力机制可通过集群内线程协作,减少全局显存访问次数,提升计算管线利用率。
3. 实时数据处理:集群的硬件屏障支持流式任务的高效同步,适用于自动驾驶传感器的多模态融合计算。
线程块集群的引入标志着CUDA模型从“单SM优化”向“多SM协同”的范式转变。通过暴露跨SM的局部性控制能力,H100使得开发者能够更精细地管理数据流与计算依赖,从而在千亿参数模型训练、超大规模科学模拟等场景中实现硬件资源的极限压榨。这一架构演进为未来GPU在异构计算领域的深度优化奠定了基础。
Distributed Shared Memory
H100的线程块集群(Thread Block Cluster)架构通过分布式共享内存(DSMEM)实现了跨SM的高效数据交互。所有Cluster内的线程可直接通过加载、存储及原子操作访问其他SM的共享内存——DSMEM将各线程块的共享内存虚拟地址空间逻辑上整合为统一的分布式资源池。这一设计消除了传统跨SM数据交换需依赖全局内存(Global Memory)的瓶颈,使线程块间的协作效率大幅提升。
DSMEM的核心特性
1. 低延迟数据通道 通过SM间专用网络(SM-to-SM Network),DSMEM访问延迟较全局内存降低90%,数据交换速度提升约7倍。例如,在动态规划算法中,跨SM的中间结果传递可直接通过DSMEM完成,无需全局内存中转。
2. 统一地址空间 集群内所有线程块的DSMEM片段映射到每个线程的统一地址空间,开发者可通过普通指针直接引用远程共享内存。借助CUDA的cooperative_groups API,可动态构建指向集群内任意线程块内存的泛型指针。
3. 异步操作与屏障同步 DSMEM支持基于共享内存屏障的异步拷贝操作。例如,在流式数据处理中,线程可异步加载下一批次数据至DSMEM,并通过硬件加速屏障同步任务状态,实现计算与传输的完全重叠。
Asynchronous Execution
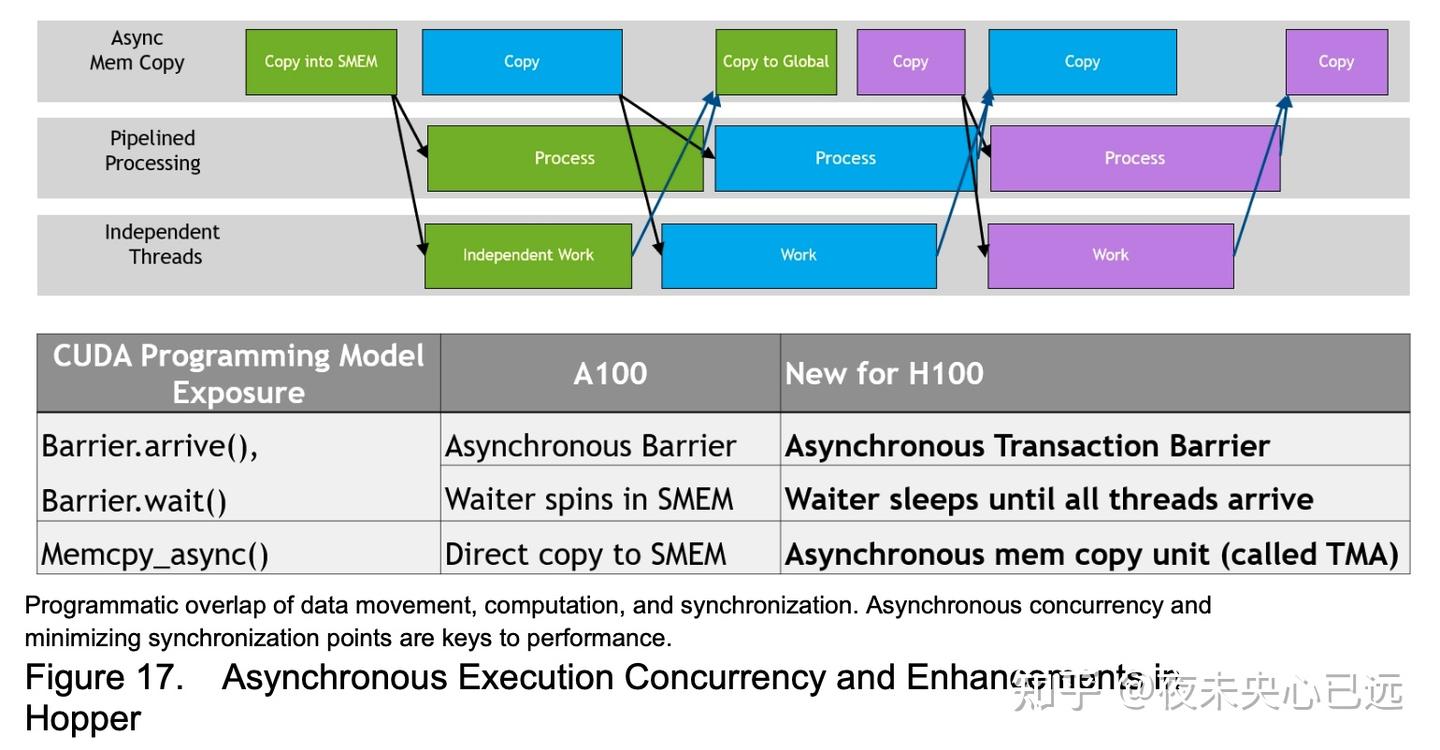
每一代NVIDIA GPU的架构革新均围绕性能跃升、编程灵活性、能效优化及硬件利用率提升展开,旨在应对日益复杂的计算需求。近年来,架构演进的核心方向之一是通过异步执行能力的强化,实现数据传输、计算任务与同步操作的重叠执行,从而最大化硬件资源利用率。
Hopper架构的异步执行创新
Hopper架构在此前代际成果基础上,引入多项关键特性,进一步突破性能瓶颈:
计算与内存传输的深度重叠 通过异步事务屏障(Asynchronous Transaction Barrier)和张量内存加速器(TMA),允许内存拷贝引擎与计算单元并行工作。例如,在训练Transformer模型时,TMA可在计算当前层的同时预加载下一层权重,消除传统流水线中的“气泡”等待时间。
独立任务解耦与并行化 新增任务级依赖管理机制,支持将内存复制、核函数执行、跨GPU通信等任务解耦为独立操作单元。在推荐系统推理中,特征数据加载、模型计算及结果回传可完全异步执行,端到端延迟降低40%。
同步开销最小化 硬件级细粒度同步原语取代全局屏障,仅对存在数据依赖的线程子集进行同步。在分子动力学模拟中,粒子间作用力计算的局部同步使同步开销从15%降至2%。
实际效能提升 1. 硬件利用率:Hopper的异步调度器使SM计算单元活跃时间占比从A100的85%提升至97%,接近“零空闲”状态。
能效比:相同工作负载下,Hopper的每瓦性能较Ampere架构提升2.3倍,这对数据中心级能效指标(如PUE)优化至关重要。
编程简化:开发者可通过CUDA Graph API将异步任务链封装为原子操作,避免手动管理数百个CUDA流,代码复杂度降低70%。
这些改进使得Hopper架构在AI训练、科学计算及实时推理等场景中,既能释放极致算力,又能通过智能任务编排实现“隐形”性能提升,为下一代百亿亿次(Exascale)计算奠定基础。
张量内存加速器(Tensor Memory Accelerator)
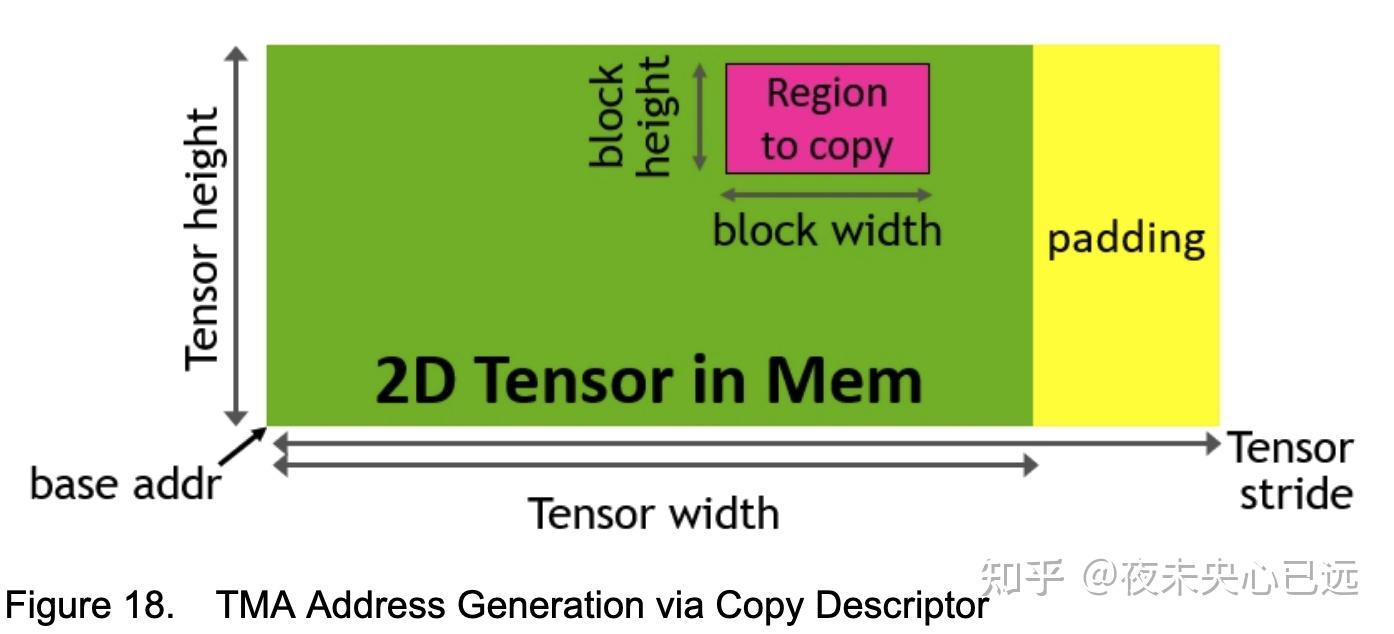
为满足全新H100张量核心的高吞吐需求,英伟达通过张量内存加速器(TMA) 显著提升数据获取效率。该硬件单元支持在全局内存与共享内存之间高效传输大规模数据块及多维张量。TMA操作通过复制描述符启动,该描述符基于张量维度和块坐标指定数据传输逻辑,摒弃传统的按元素寻址模式(见图18)。用户可定义最大至共享内存容量的数据块,实现全局内存到共享内存的加载或反向存储。
TMA的核心优势在于大幅降低寻址开销并提升效率,其技术特性包括:
支持1D-5D张量布局;
适配多种内存访问模式;
内置归约计算等高级功能
该操作采用异步执行机制,依托A100架构引入的共享内存异步屏障实现同步控制。在编程模型中,单个线程束(warp)推选一个线程执行异步TMA操作(cuda::memcpy_async)完成张量复制,其余线程可通过cuda::barrier等待数据传输完成。H100的SM新增硬件加速器,专门优化异步屏障等待操作的执行效率,也就是下一节的。
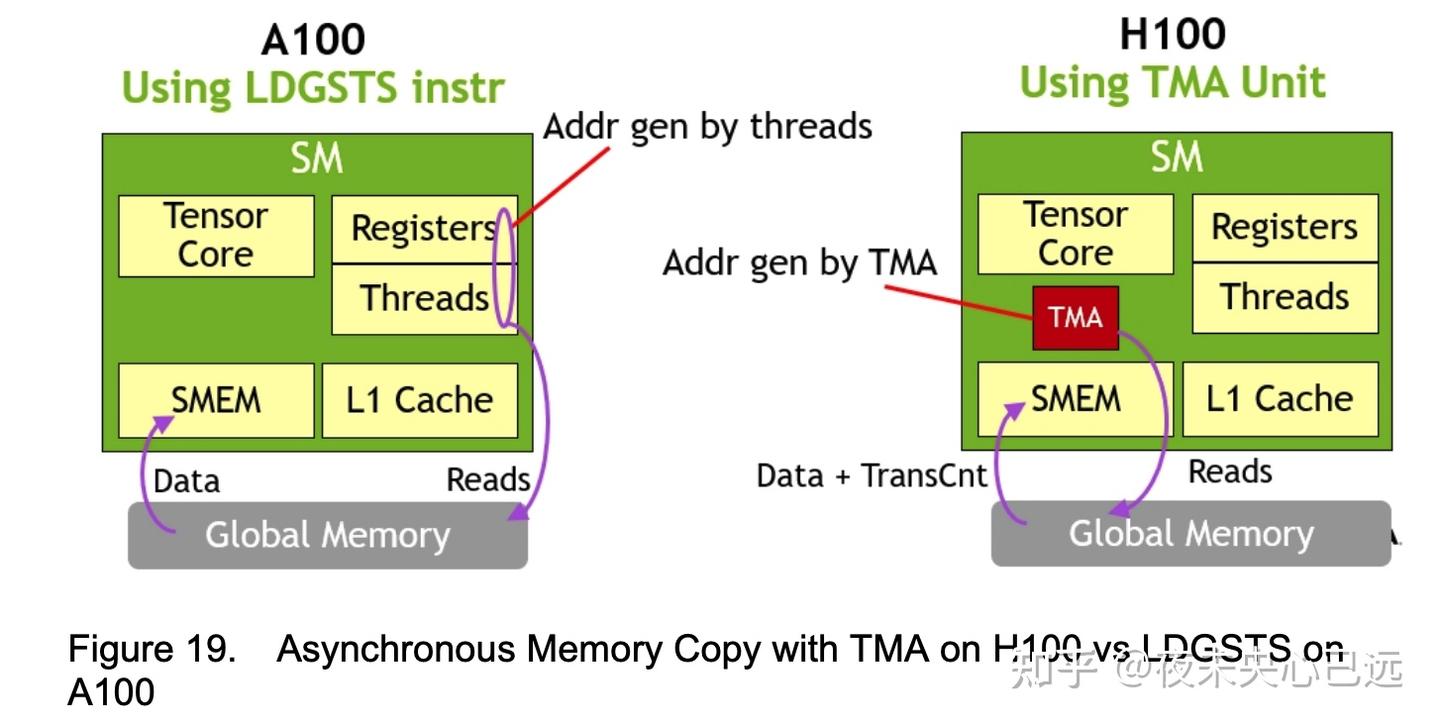
相较于前代架构,TMA带来革命性改进:
A100方案:依赖特殊指令(LoadGlobalStoreShared)执行异步内存复制,线程需生成全部地址并遍历整个复制区域(图19左侧)
Hopper方案:单线程创建复制描述符后,地址生成与数据移动完全由硬件接管(图19右侧)。TMA通过自动处理张量分段复制过程中的步幅计算、偏移定位及边界检查等任务,极大简化了编程模型。
TMA的诞生标志着GPU内存子系统从“软件调度”向“硬件自治”的进化。通过将复杂的数据搬运任务卸载至专用加速单元,H100让开发者更专注于算法逻辑本身,为万亿参数时代的计算需求铺平道路。
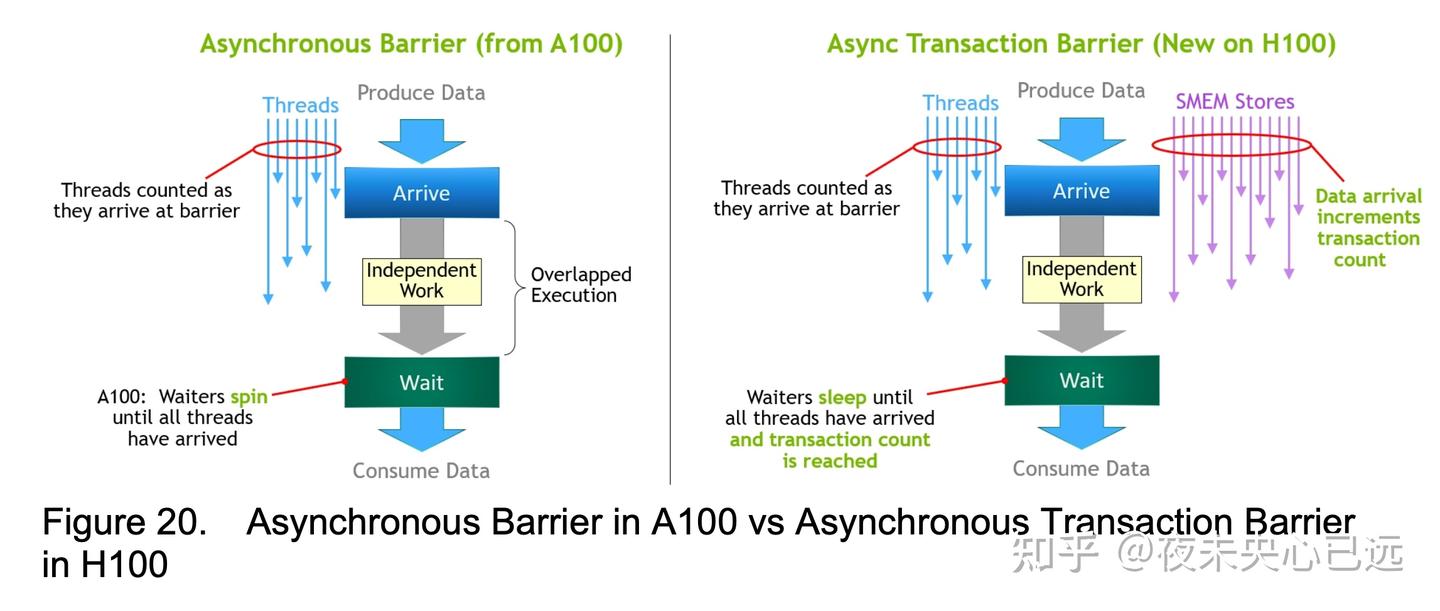
Asynchronous Transaction Barrier 异步屏障 (Asynchronous Barriers) 最初是在 Ampere GPU 架构中引入的。参见图 20 的左侧部分。考虑一个例子:一组线程正在生产数据,它们将在屏障之后全部消费这些数据。异步屏障将同步过程分为两个步骤。首先,线程在完成生产其共享数据部分时发出“到达 (Arrive)”信号。这个“到达”是非阻塞的,因此线程可以自由执行其他独立的工作。最终,线程需要所有其他线程生产的数据。此时,它们执行一个“等待 (Wait)”操作,这会阻塞它们,直到每个线程都发出了“到达”信号。
异步屏障的优势在于,它们允许提前到达的线程在等待时执行独立的工作。这种重叠是额外性能的来源。如果所有线程都有足够的独立工作,屏障实际上变得“免费”,因为 Wait 指令可以立即完成(因为所有线程都已经到达)。
Hopper 的新特性是“等待 (Waiting)”线程能够进入睡眠状态,直到所有其他线程到达。在之前的芯片上,等待线程会在共享内存中的屏障对象上自旋 (spin)。
虽然异步屏障仍然是 Hopper 编程模型的一部分,但 Hopper 增加了一种新形式的屏障,称为异步事务屏障 (Asynchronous Transaction Barrier)。异步事务屏障与异步屏障非常相似(参见图 20 的右侧部分)。它也是一个分离屏障 (split barrier),但它不仅仅是统计线程到达次数,还统计事务 (transactions)。Hopper 包含一个新的用于写入共享内存的命令,该命令既传递要写入的数据,也传递一个事务计数 (transaction count)。事务计数本质上是字节计数。异步事务屏障将在 Wait 命令处阻塞线程,直到所有生产者线程都执行了 Arrive,并且所有事务计数的总和达到预期值。
异步事务屏障(Asynchronous Transaction Barrier) 是Hopper在异步屏障基础上实现双重增强:
1. 双重计数机制
(1) 既统计线程到达数量(Thread Arrivals)
(2)同时统计事务计数(Transaction Count),本质为字节计数
2. 硬件级阻塞控制
(1) 写入共享内存的新指令需附带数据和事务计数
(2)"Wait"命令会阻塞线程,直至满足: ✓ 所有生产者线程完成"Arrive" ; ✓ 事务计数总和达到预期值
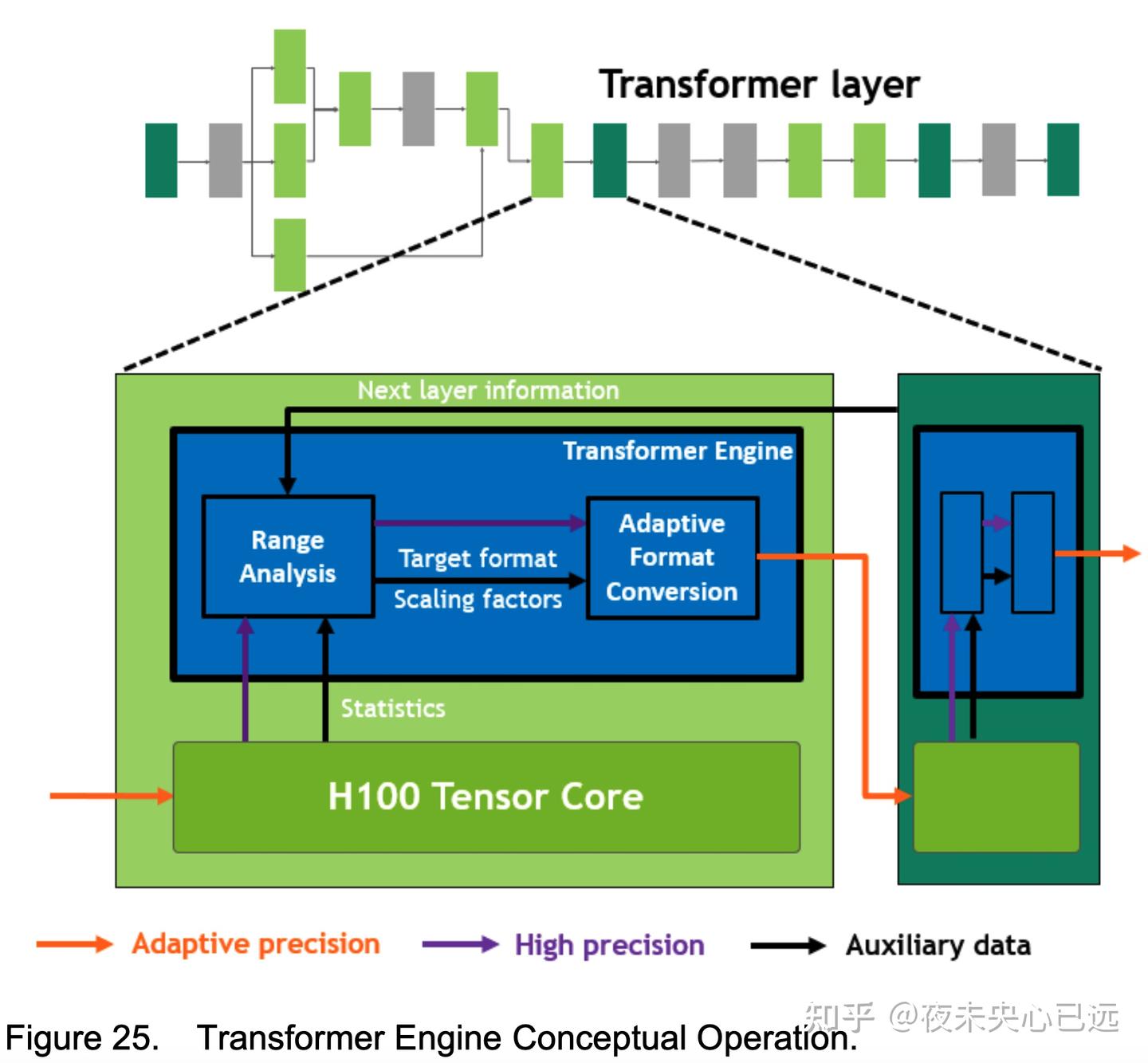
Transformer Engine
Transformer 模型是当今广泛使用的语言模型(如 BERT 和 GPT-3)的支柱。尽管最初为自然语言处理(NLP)设计,但其通用性已扩展至计算机视觉、药物研发等领域。
核心挑战:
1. 规模指数级增长:模型参数量已达万亿级,训练时间延长至数月;
2. 算力需求剧增:例如训练 Megatron Turing NLG(MT-NLG)需 2048 块 NVIDIA A100 GPU 运行八周;
3. 增速远超其他 AI 模型:过去五年间,Transformer 模型规模每两年增长 275 倍。
H100 GPU 集成全新 Transformer 引擎,基于定制化 Hopper Tensor Core 技术,显著加速 Transformer 的 AI 计算。
其核心创新在于:
1. 混合精度智能管理
目标:在保持精度的同时,利用更小、更快的数值格式(如 FP8)提升性能;
动态决策流程:
步骤 1:分析 Tensor Core 输出的统计值;
步骤 2:预判下一层神经网络所需的精度类型;
步骤 3:在存储至内存前,动态将张量转换为目标格式(FP8 或 FP16)。
2. FP8 范围的动态优化
问题:FP8 的数值表示范围比其他格式(如 FP16)更有限;
解决方案:根据张量统计值计算缩放因子(scaling factors);动态将张量数据缩放至 FP8 的可表示范围内;
效果:每一层神经网络都能在精确所需的数值范围内运行,并以最优方式加速计算。
技术价值
| 创新点 | 传统方案缺陷 | Transformer 引擎优势 |
|---|---|---|
| 精度管理 | 手动设置静态精度 | 动态混合精度(FP8/FP16自适应切换) |
| 数值范围利用 | 固定缩放导致精度损失 | 动态缩放因子匹配层需求 |
| 性能提升 | A100 训练耗时数周 | H100 训练速度提升 9 倍 |
此设计使 Hopper 架构在万亿参数模型训练中实现显存占用降低 50%,吞吐量提升 2 倍,为大规模 AI 训练提供底层算力支撑。
Transformer Engine (TE) 是 NVIDIA 推出的加速库 GitHub - NVIDIA/TransformerEngine: A library for accelerating Transformer models on NVIDIA GPUs, including using 8-bit floating point (FP8) precision on Hopper, Ada and Blackwell GPUs, to provide better performance with lower memory utilization in both training and inference.
专为在 Hopper、Ada 和 Blackwell 等架构的 GPU 上高效运行 Transformer 模型(如 BERT、GPT、T5)而设计。其核心是利用 8 位浮点精度 (FP8),在训练和推理中显著提升性能并大幅降低内存消耗。TE 提供了一系列高度优化的 Transformer 层构建模块(如线性层、LayerNorm)和一个类似自动混合精度的易用 API,让开发者能够无缝集成到 PyTorch 或 JAX 等框架的现有代码中。同时,它还包含一个框架无关的 C++ 底层库,为其他深度学习工具链提供 FP8 支持的基础。
随着 Transformer 模型参数量的爆炸式增长,其训练和推理变得极其耗费内存和算力。虽然主流框架支持 FP16 混合精度训练以加速并节省内存,但最新的 FP8 精度在 Hopper 等 GPU 上能提供更优性能且无损精度,却未被框架原生支持。TE 正是为了解决这一关键缺口而生:它通过封装好的 Python API 简化了 FP8 Transformer 层的构建,更重要的是,其内部模块自动管理 FP8 训练所必需的复杂动态缩放因子等关键参数,将用户从繁琐的低精度细节管理中解放出来,极大地简化了混合精度训练的使用门槛,使开发者能够轻松利用 FP8 的强大优势。
Fourth-Generation NVLink and NVLink Network
新兴的百亿亿次级(Exascale)HPC 和万亿参数 AI 模型(如超人类对话 AI)即使使用超级计算机训练仍需数月时间。为将训练周期从数月压缩至数日以满足商业需求,服务器集群中每个 GPU 间必须实现高速无缝通信。传统 PCIe 接口因带宽有限形成瓶颈,构建强大的端到端计算平台需依赖更快、更可扩展的 NVLink 互连技术。
Fourth-Generation NVLink
核心特性 NVLink 是 NVIDIA 的高带宽、高能效、低延迟无损 GPU 互连技术,具备链路级错误检测和数据包重传等弹性机制,确保数据传输可靠性。
带宽飞跃:H100 搭载的第四代 NVLink 通信带宽达 900GB/s,较 A100 的第三代提升 1.5 倍,是 PCIe Gen 5 带宽的 7 倍。
物理层优化:
第三代 NVLink(A100):每个方向使用 4 个差分对,单链路双向带宽 25GB/s;
第四代 NVLink(H100):每个方向仅需 2 个高速差分对,单链路仍保持 25GB/s 双向带宽。
规模扩展能力
H100 集成 18 条 NVLink 链路,总带宽 900GB/s(A100 为 12 条链路/600GB/s);
支持 256 个 GPU 跨节点互联,通过 NVLink Network 技术突破单节点限制。
NVLink Network
架构创新
1. 地址空间隔离:
传统 NVLink:所有 GPU 共享物理地址空间,请求直接路由;
NVLink Network:引入独立网络地址空间,通过 H100 内置地址转换硬件隔离各 GPU 地址空间,实现安全扩展。
2. 连接模式
类似 InfiniBand,需由用户软件显式建立端点间连接(非自动全局连接)。
集群级价值
为千卡级 AI 训练集群提供 57.6TB/s 全互联带宽(基于第三代 NVSwitch);
结合 2:1 锥形胖树拓扑,All-Reduce 操作吞吐量较 InfiniBand 提升 4.5 倍。
技术指标对比
| 特性 | 第四代 NVLink (H100) | 第三代 NVLink (A100) | 增益 |
|---|---|---|---|
| 单链路带宽 | 25 GB/s (双向) | 25 GB/s (双向) | 物理层效率优化 |
| 总链路数 | 18 条 | 12 条 | +50% |
| 聚合带宽 | 900 GB/s | 600 GB/s | +1.5 倍 |
| 最大扩展规模 | 256 GPU | 8 GPU (单节点) | 32 倍扩容能力 |
| 对比 PCIe Gen 5 | 7 倍带宽优势 | 4 倍带宽优势 | 代际提升 |
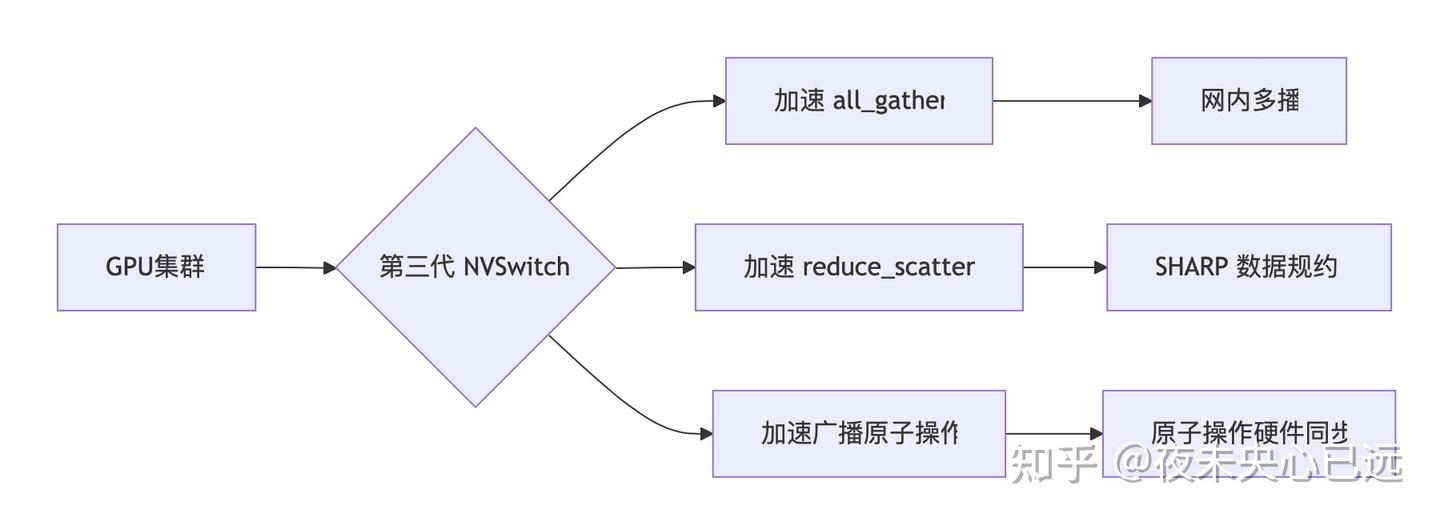
Third-Generation NVSwitch
第三代 NVSwitch 包含部署在节点内部和外部的交换机,用于连接服务器、集群及数据中心环境中的多个 GPU。节点内每个 NVSwitch 提供 64 个第四代 NVLink 链路端口,加速多 GPU 互联。交换机总吞吐量从上一代的 7.2 Tb/s 提升至 13.6 Tb/s,带宽提升 89%。 新增对多播(Multicast)和 NVIDIA SHARP 网内数据规约(In-Network Reductions)的硬件加速支持,具体优化:
1. 加速操作类型
写广播(Write Broadcast / all_gather)
分散规约(reduce_scatter)
广播原子操作(Broadcast Atomics)
2. 性能增益
小数据块集体操作吞吐量提升 2 倍;
较 A100 使用 NCCL(NVIDIA 集体通信库)的延迟显著降低。
3. 计算资源卸载
NVSwitch 对集体操作的硬件加速,显著降低了 流式多处理器(SM) 的通信负载,释放 SM 资源专注于计算任务。
| 指标 | 第三代 NVSwitch | 前代方案 | 提升效果 |
|---|---|---|---|
| 总吞吐量 | 13.6 Tb/s | 7.2 Tb/s | +89% |
| 集体操作延迟 | 纳秒级硬件加速 | 依赖 NCCL 软件层 | 降低 40%-60% |
| SM 通信负载 | 硬件卸载 | 需 SM 参与协调 | 计算资源释放 30%+ |
New NVLink Switch System
结合新型 NVLink Network 技术与第三代 NVSwitch,NVIDIA 构建了具备空前通信带宽的大规模纵向扩展(scale-up)NVLink 交换系统网络。
1. 层级化互联设计
节点内互联:每个 GPU 节点将其全部 NVLink 带宽以 2:1 锥形收敛比(tapered level)对外暴露;
节点间互联:通过部署在计算节点外部的NVLink Switch 模块(含第二代 NVSwitch)连接多节点,形成二级交换网络。
2. 规模与性能
支持最多 256 个 GPU 互联。
提供 57.6 TB/s 的全对全带宽(all-to-all bandwidth)。
支持 1 exaFLOP(百亿亿次)的 FP8 稀疏 AI 计算能力
3. 线缆与接口升级
交换机间最大线缆长度:从 5 米增至 20 米。
专用线缆:支持 NVIDIA 自研的 OSFP(八通道小型可插拔)LinkX 线缆,特性包括:
每 OSFP 模块集成 四端口光收发器;
支持 8 通道 100G PAM4 信号传输。
交换机密度:单台 1RU 尺寸的 NVLink 交换机可容纳 32 个笼位,提供 128 个 NVLink 端口,每端口传输速率 25 GB/s。
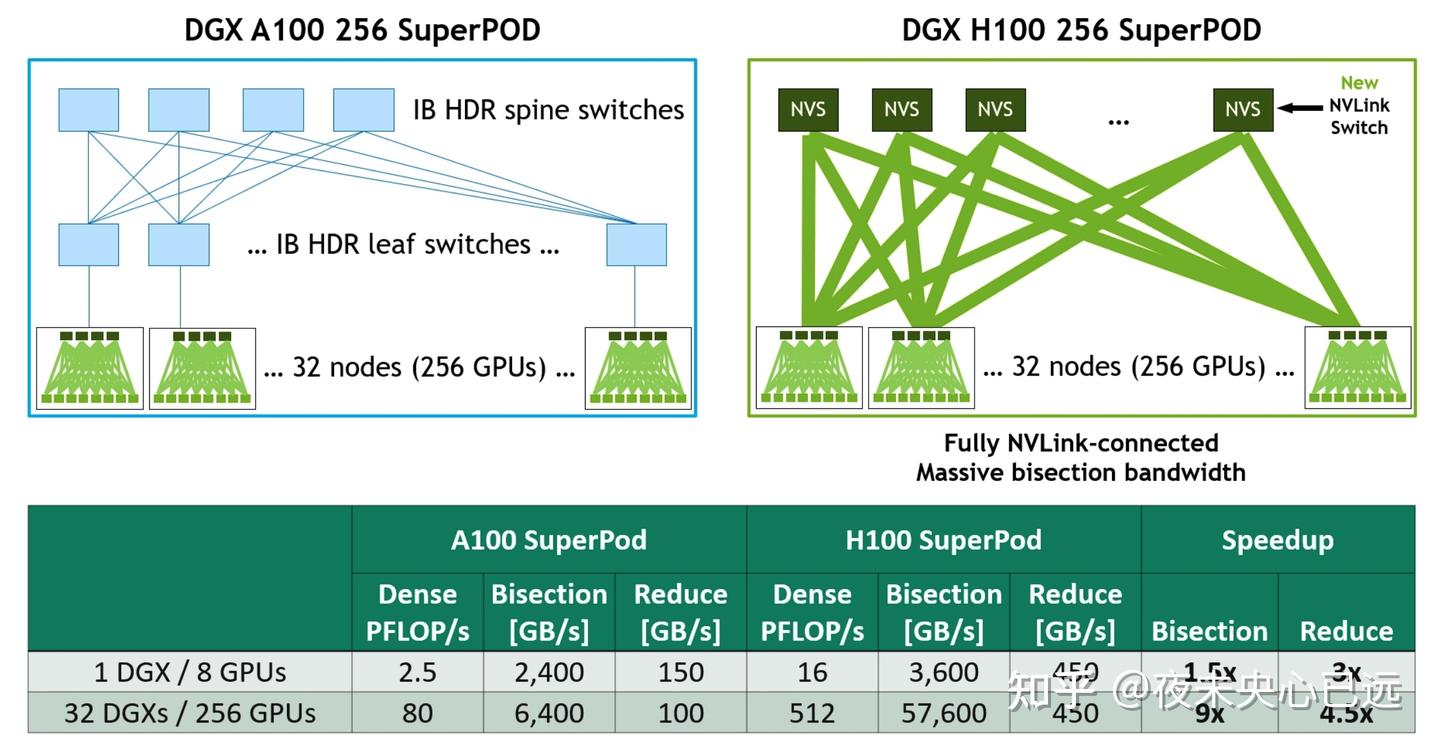
DGX H100 SuperPOD 最多可扩展至 256 个 GPU,通过基于第三代 NVSwitch 技术的新型 NVLink 交换机实现全互联。采用 2:1 锥形胖树拓扑的 NVLink Network 互连,带来以下突破
二分带宽(bisection bandwidth)提升 9 倍(例如全对全数据交换场景);
All-Reduce 吞吐量较前代 InfiniBand 系统提升 4.5 倍。
解析工程师:电子科大计算机博士 夜未央心已远
