


GPU服务器部署完整指南
1. 系统初始化与基础配置
1.1 系统更新与基础工具
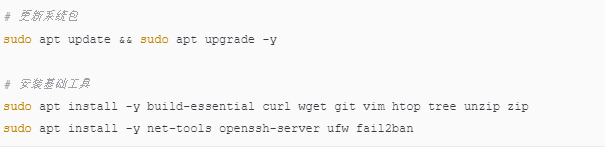
1.2 创建部署用户(推荐)
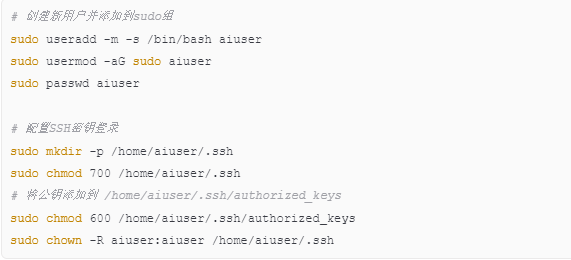
1.3 系统安全配置

2. NVIDIA驱动与CUDA安装
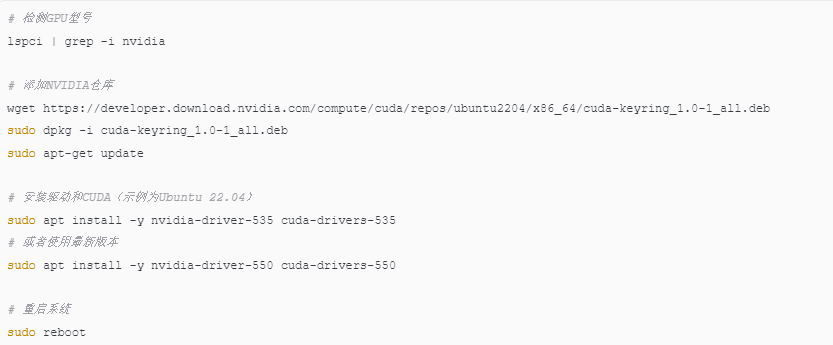
2.1 安装NVIDIA驱动
2.2 验证安装
bash
检查驱动
nvidia-smi
检查CUDA
nvcc --version
检查GPU可用性
nvidia-smi -L
3. Docker与NVIDIA Container Toolkit
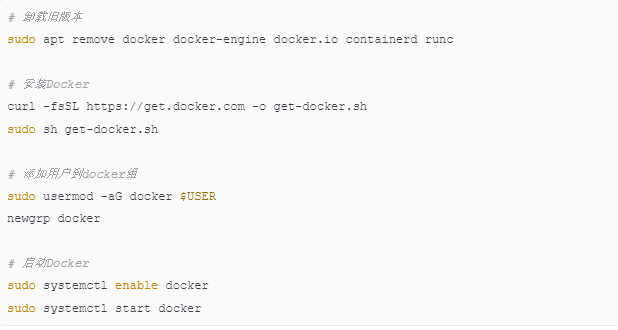
3.1 安装Docker
3.2 安装NVIDIA Container Toolkit

3.3 验证Docker GPU支持
bash
测试GPU在容器中是否可用
docker run --rm --gpus all nvidia/cuda:12.1-base nvidia-smi
4. Python深度学习环境
4.1 安装Miniconda
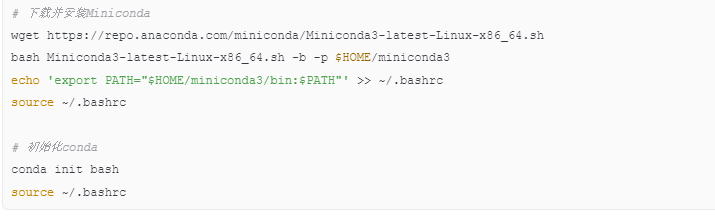
4.2 创建深度学习环境

4.3 验证深度学习环境

5. 常用深度学习框架部署
5.1 Jupyter Lab配置
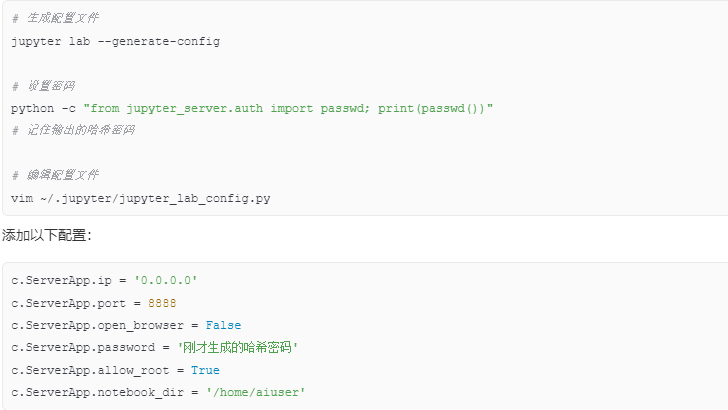
5.2 创建系统服务

5.3 TensorBoard配置
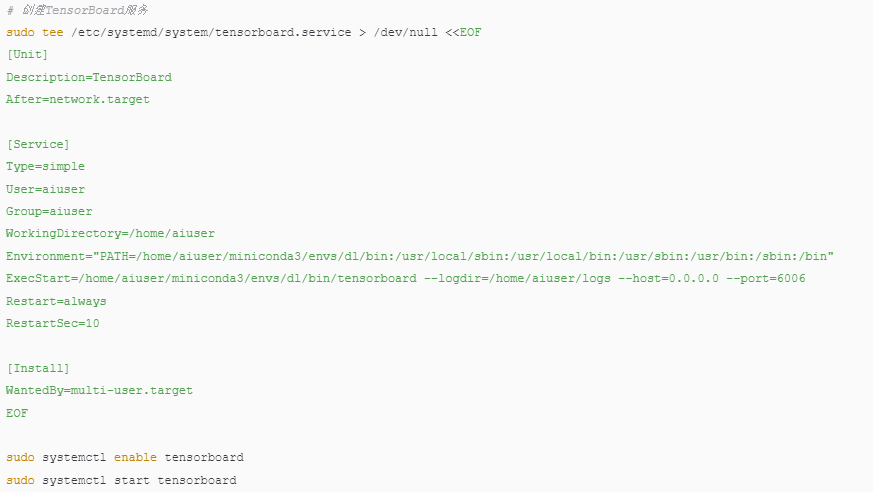
6. 常用工具与库
6.1 机器学习工具

6.2 计算机视觉

6.3 自然语言处理
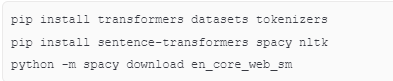
6.4 系统监控工具

7. 数据存储与备份
7.1 配置数据目录

7.2 配置自动备份

8. 生产环境部署
8.1 Docker Compose环境

8.2 示例Docker Compose配置

9. 性能优化与监控
9.1 GPU性能调优
bash
设置持久化模式
sudo nvidia-smi -pm 1
设置GPU时钟频率(可选)
sudo nvidia-smi -ac 5001,1590
查看GPU利用率
watch -n 1 nvidia-smi
9.2 系统监控脚本

10. 部署检查清单
10.1 基础检查
- [ ] 系统已更新到最新版本
- [ ] NVIDIA驱动正确安装(nvidia-smi正常显示)
- [ ] CUDA工具包安装完成(nvcc --version正常)
- [ ] Docker和NVIDIA Container Toolkit安装完成
- [ ] Python环境创建成功
- [ ] PyTorch/TensorFlow GPU版本安装成功
10.2 服务检查
- [ ] Jupyter Lab服务运行正常(端口8888)
- [ ] TensorBoard服务运行正常(端口6006)
- [ ] 防火墙配置正确
- [ ] SSH密钥登录配置完成
- [ ] 自动备份脚本配置完成
10.3 性能检查
- [ ] GPU持久化模式已启用
- [ ] 监控脚本运行正常
- [ ] 数据目录结构完整
- [ ] 备份策略生效
11. 常用命令速查
11.1 GPU相关
bash
查看GPU状态
nvidia-smi
watch -n 1 nvidia-smi # 实时监控
查看GPU进程
nvidia-smi pmon -i 0 -s um
杀死GPU进程
nvidia-smi --gpu-reset -i 0
11.2 Docker相关
bash
运行GPU容器
docker run --gpus all nvidia/cuda:12.1-base nvidia-smi
构建GPU镜像
docker build --tag my-gpu-app .
查看容器GPU使用情况
docker stats
11.3 环境管理
bash
激活环境
conda activate dl
查看已安装包
conda list
导出环境
conda env export > environment.yml
从文件创建环境
conda env create -f environment.yml
12. 故障排除
12.1 常见问题
1. NVIDIA驱动问题
- 症状:nvidia-smi报错
- 解决:重新安装驱动,检查内核版本匹配
2. CUDA版本不匹配
- 症状:PyTorch/TensorFlow无法识别GPU
- 解决:确保CUDA版本与框架要求匹配
3. Docker GPU权限问题
- 症状:docker run --gpus all报错
- 解决:检查用户是否在docker组,重启docker服务
4. 内存不足
- 症状:训练时报CUDA OOM
- 解决:减少batch size,使用梯度累积
12.2 获取帮助
bash
查看系统日志
journalctl -u jupyter
journalctl -u tensorboard
查看Docker日志
docker logs container_name
查看GPU详细信息
nvidia-smi -q -d MEMORY,UTILIZATION,PIDS,TEMPERATURE
**部署完成后,您将拥有一个功能完整的GPU服务器,支持深度学习训练、模型部署和实验管理。建议定期更新驱动和框架版本,保持系统安全和性能最优。
