


本周三,AMD正式发布备受瞩目的全新MI300系列AI芯片,其中包括MI300A和MI300X芯片。这一系列芯片旨在瞄准英伟达主导的市场,为人工智能训练提供更优异的性能和处理能力。据官方数据显示,该显卡相较于英伟达H100显卡,最多可以提升60%的性能,为用户带来了更出色的计算体验。相较于传统计算机处理器,这种专用AI芯片在处理人工智能训练所涉及的大型数据集方面表现更加出色。
猿界算力认为,MI300系列AI芯片的发布标志着AMD在人工智能领域的重要进展。它们采用了先进的封装技术,内存优化设计,更优秀的架构和设计,以满足日益增长的人工智能训练需求。这些芯片在处理复杂的神经网络模型和大规模数据集时表现出色,能够以更高的效率进行计算、并行处理和加速模型训练过程。
AMD发布的新款芯片拥有超过1500亿个晶体管,在封装技术方面,两颗芯片都采用采用了一种名为“3.5D封装“的技术来生产,并且也都是基于 AMD第四代的Infinity架构打造。

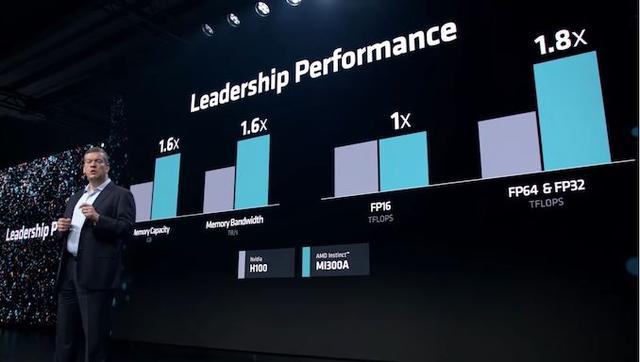
在内存方面,两颗芯片都采用了现下大热的HBM 3设计,但是MI 300A用的是 128GB的 HBM 3设计,MI 300X 用的是内存更大的 192GB HBM 3设计,MI300X内存是英伟达H100产品的2.4倍,内存带宽是H100的1.6倍,进一步提升了性能;
在计算单元方面,MI 300X 搭载了304个CDNA 3 计算单元,每个计算单元中还有34个计算单位。而MI 300A的计算单元更少,只有228个。
在整个发布会上,AMD将MI300X芯片与英伟达H100进行了全程对标。根据官方披露的数据,MI300X的内存配置是英伟达H100的2.4倍,峰值存储带宽也是英伟达的2.4倍。此外,MI300X在FP8、FP16和TF32算力方面超过了英伟达H100约1.3倍。

在AI芯片生态中,软件是不可或缺的一环。此前的发布会上,AMD介绍了他们的AI软件套件ROCm。与英伟达专用的CUDA不同,ROCm是一个开放且开源的平台,为用户提供更灵活和可定制的开发环境。
本次发布会展示了AMD在AI芯片领域的竞争实力以及对英伟达H100的对标。MI300X芯片在内存配置、存储带宽和算力等方面提供了显著的突破,并通过开放的软件生态系统更好地满足用户的需求。这对于用户来说,无疑提供了更多选择和更具竞争力的解决方案。有望挑战英伟达在炙手可热的人工智能加速器市场上的地位。
猿界算力作为AI芯片的下游服务商,意识到了AMD发布的MI300X芯片带来的技术突破和性能提升。这意味着猿界可以更好地利用这样高性能的AI芯片,为客户提供更强大的AI服务和解决方案。

这次发布会为猿界提供了一个新的机会,能够与AMD建立更紧密的合作关系。作为AMD的合作伙伴,猿界可以通过与AMD进行深度合作,获得对MI300X芯片的早期访问和技术支持。这将使猿界能够更早地了解并掌握MI300X芯片的技术特点和优势,从而为客户提供更加先进和创新的AI解决方案。
