


海外:模型、应用和算力相互推进
2 月 16 日,OpenAI 发布了首个文生视频模型 Sora。Sora 可以直接输出长达 60 秒 的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。 3 月 4 日,Anthropic 发布了新一代 AI 大模型系列——Claude 3。该系列包含三 个模型,按能力由弱到强排列分别是 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus。 其中,能力最强的 Opus 在多项基准测试中得分都超过了 GPT-4 和 Gemini 1.0 Ultra, 在数学、编程、多语言理解、视觉等多个维度树立了新的行业基准。Claude 首次带来了 对多模态能力的支持(Opus 版本的 MMMU 得分为 59.4%,超过 GPT-4V,与 Gemini 1.0 Ultra 持平)。
3 月 18 日,马斯克开源大模型 Grok-1。马斯克旗下 AI 初创公司 xAI 宣布,其研发 的大模型 Grok-1 正式对外开源开放,用户可直接通过磁链下载基本模型权重和网络架 构信息。xAI 表示,Grok-1 是一个由 xAI 2023 年 10 月使用基于 JAX 和 Rust 的自定义 训练堆栈、从头开始训练的 3140 亿参数的混合专家(MOE)模型,远超 OpenAI 的 GPT 模型。 在 CEO 奥尔特曼的带领下,OpenAI 或许有望在今年夏季推出 GPT-5。 3 月 23 日,媒体援引知情人士透露,OpenAI 计划下周在美国洛杉矶与好莱坞的影 视公司和媒体高管会面。OpenAI 希望与好莱坞合作,并鼓励电影制作人将 OpenAI 最新 AI 视频生成工具 Sora 应用到电影制作中,从而拓展 OpenAI 在娱乐行业的影响力。
3 月 19 日,英伟达 GTC 大会上,英伟达发布新的 B200 GPU,以及将两个 B200 与单个 Grace CPU 相结合的 GB200。 全新 B200 GPU 拥有 2080 亿个晶体管,采用台积电 4NP 工艺节点,提供高达 20 petaflops FP4 的算力。与 H100 相比,B200 的晶体管数量是其(800 亿)2 倍多。而单 个 H100 最多提供 4 petaflops 算力,直接实现了 5 倍性能提升。 而 GB200 是将 2 个 Blackwell GPU 和 1 个 Grace CPU 结合在一起,能够为 LLM 推理工作负载提供 30 倍性能,同时还可以大大提高效率。
计算能力不断提升。过去,训练一个 1.8 万亿参数的模型,需要 8000 个 Hopper GPU 和 15MW 的电力。如今,2000 个 Blackwell GPU 就能完成这项工作,耗电量仅为 4MW。 在 GPT-3(1750 亿参数)大模型基准测试中,GB200 的性能是 H100 的 7 倍,训练速度 是 H100 的 4 倍。
2. 国内模型逐步追赶,提升算力需求
Kimi 逐渐走红。月之暗面 Kimi 智能助手 2023 年 10 月初次亮相时,凭借约 20 万 汉字的无损上下文能力,帮助用户解锁了专业学术论文的翻译和理解、辅助分析法律问 题、一次性整理几十张发票、快速理解 API 开发文档等,获得了良好的用户口碑和用户 量的快速增长。 2024 年 3 月 18 日,Kimi 智能助手在长上下文窗口技术上再次取得突破,无损上 下文长度提升了一个数量级到 200 万字。 过去要 10000 小时才能成为专家的领域,现在只需要 10 分钟,Kimi 就能接近任 何一个新领域的初级专家水平。用户可以跟 Kimi 探讨这个领域的问题,让 Kimi 帮助 自己练习专业技能,或者启发新的想法。有了支持 200 万字无损上下文的 Kimi,快速 学习任何一个新领域都会变得更加轻松。
访问量提升,kimi 算力告急。3 月 21 日下午,大模型应用 Kimi 的 APP 和小程序 均显示无法正常使用,其母公司月之暗面针对网站异常情况发布说明:从 3 月 20 日 9 点 30 分开始,观测到 Kimi 的系统流量持续异常增高,流量增加的趋势远超对资源的预 期规划。这导致了从 20 日 10 点开始,有较多的 SaaS 客户持续的体验到 429:engine is overloaded 的异常问题,并对此表示深表抱歉。 2024 年 3 月 23 日,阶跃星辰发布 Step 系列通用大模型。产品包括 Step-1 千亿参 数语言大模型、Step-1V 千亿参数多模态大模型,以及 Step-2 万亿参数 MoE 语言大模 型的预览版,提供 API 接口给部分合作伙伴试用。 相比于 GPT-3.5 是一个千亿参数模型,GPT-4 是拥有万亿规模参数,国内大模型厂商如果想追赶,需要各个维度要求都上一个台阶。 阶跃星辰发布了万亿参数大模型预览版,标志着国产 AI 大模型取得了巨大进步。 国产 AI 大模型正在不断迭代,对算力需求会不断提升。
3. 国内算力产业现状盘点
3.1. 算力有哪些核心指标?
算力芯片的主要参数指标为算力浮点数,显存,显存带宽,功耗和互连技术等。 算力浮点数:算力最基本的计量单位是 FLOPS,英文 Floating-point Operations Per Second,即每秒执行的浮点运算次数。算力可分为双精度(FP64),单精度(FP32),半精度 (FP16)和 INT8。FP64 计算多用于对计算精确度要求较高的场景,例如科学计算、物理 仿真等;FP32 计算多用于大模型训练等场景;FP16 和 INT8 多用于模型推理等对精度 要求较低的场景。

GPU 显存:显存用于存放模型,数据显存越大,所能运行的网络也就越大。
在预训练阶段,大模型通常选择较大规模的数据集获取泛化能力,因此需要较大的 批次等来保证模型的训练强大。而模型的权重也是从头开始计算,因此通常也会选择高 精度(如 32 位浮点数)进行训练。需要消耗大量的 GPU 显存资源。 在微调阶段,通常会冻结大部分参数,只训练小部分参数。同时,也会选择非常多 的优化技术和较少的高质量数据集来提高微调效果,此时,由于模型已经在预训练阶段 进行了大量的训练,微调时的数值误差对模型的影响通常较小。也常常选择 16 位精度 训练。因此通常比预训练阶段消耗更低的显存资源。 在推理阶段,通常只是将一个输入数据经过模型的前向计算得到结果即可,因此需 要最少的显存即可运行。 显存带宽:是运算单元和显存之间的通信速率,越大越好。 互连技术:一般用于显存之间的通信,分布式训练,无论是模型并行还是数据并行, GPU 之间都需要快速通信,不然就是性能的瓶颈。
3.2. 国产算力和海外的差距
从单芯片能力看,训练产品与英伟达仍有 1-2 代硬件差距。根据科大讯飞,华为昇 腾 910B 能力已经基本做到可对标英伟达 A100。推理产品距离海外差距相对较小。
从片间互联看,片间和系统间互联能力较弱。国产 AI 芯片以免费 CCIX 为主,生 态不完整,缺少实用案例,无 NV-Link 类似的协议。大规模部署稳定性和规模性距离海 外仍有较大差距。 从生态看,大模型多数需要在专有框架下才能发挥性能,软件生态差距明显,移植 灵活性,产品易用性与客户预期差距较大。客户如果使用国产 AI 芯片,需要额外付出 成本。 从研发能力看,产品研发能力(设计与制程),核心 IP(HBM,接口等)等不足, 阻碍了硬件的性能提升。
3.3. 国产化和生态抉择
海外制裁后,AI 芯片国产化诉求加大。主要系供应链安全和政策强制要求。 2024 年 3 月 22 日,上海市通信管理局等 11 个部门联合印发《上海市智能算力基础 设施高质量发展 “算力浦江”智算行动实施方案(2024-2025 年)》。到 2025 年,上海 市市新建智算中心国产算力芯片使用占比超过 50%,国产存储使用占比超过 50%,服 务具有国际影响力的通用及垂直行业大模型设计应用企业超过 10 家。 但国产 AI 芯片由于生态、稳定性、算力等问题,目前较多用于推理环节,少数用于训练。如用于训练,则需花费较多人员进行技术服务,额外投入资源较大。 华为与讯飞构建昇腾万卡集群。2023 年 10 月 24 日,科大讯飞携手华为,宣布 首个支撑万亿参数大模型训练的万卡国产算力平台“飞星一号”正式启用。1 月 30 日, 讯飞星火步履不停,基于“飞星一号”,启动了对标 GPT-4 的更大参数规模的大模型训 练。 “飞星一号“是科大讯飞和华为联合发布基于昇腾生态的国内首个可以训练万亿浮 点参数大模型的大规模算力平台。也是国内首个已经投产使用的全国产大模型训练集群, 采用昇腾 AI 硬件训练服务器和大容量交换机构建参数面无损 ROCE 组网,配置高空 间的全闪和混闪并行文件系统,可支撑万亿参数大模型高速训练。
3.4. 国内算力厂商竞争要素
在中国市场,算力行业的核心竞争要素为供应链安全、服务能力、政府关系、资金、 技术、人才等。 供应链安全。受美国制裁影响,众多算力芯片厂商芯片供应链出现问题。如果能够 解决供应链问题,持续为客户供应芯片,将是一大核心竞争力。 服务能力。AI 算力集群的构建后续的运维需要强大的服务支持,对于生态基础较弱 的国产芯片厂商要求更高。 政府关系。国产 AI 芯片的采购一大驱动为政策支持,具有良好的政府关系和客户 渠道,可以打开市场空间。 资金、技术和人才。AI 芯片的研发和突破需要大量的资源投入,我们看好具备强大 资金、技术和人才储备的公司。
3.5. 国内 AI 算力市场空间
IDC 报告预计,2023 年中国人工智能服务器市场规模将达 91 亿美元,同比增长 82.5%,2027 年将达到 134 亿美元,2022-2027 年年复合增长率达 21.8%。
算力需求市场空间巨大。在英伟达 GTC 大会上,黄仁勋讲到,如果要训练一个 1.8 万亿参数量的 GPT 模型,需要 8000 张 Hopper GPU,消耗 15 兆瓦的电力,连续跑上 90 天。如果中国有十家大模型公司,则需要 8 万张 H100 GPU。我们预计,推理算力需求 将是训练的数倍,高达几十万张 H100。随着模型继续迭代,算力需求只会越来越大。 随着国产化率逐步提升,我们预计 AI 芯片逐步成为国内芯片的主要组成。
4. 国内供给端:昇腾一马当先,各家竞相发展
北京商报对华为公司董事长梁华的主题演讲的分享中提到,昇腾已经在华为云和 28 个城市的智能算力中心大规模部署,根据财联社报道,2022 年昇腾占据国内智算中 心约 79%的市场份额。
4.1. 昇腾计算产业链
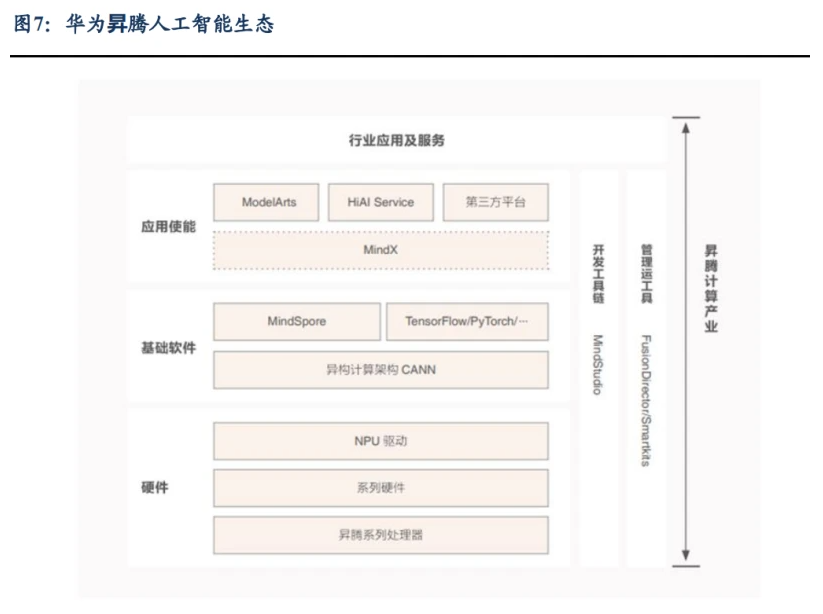
华为主打 AI 芯片产品有 310 和 910B。310 偏推理,当前主打产品为 910B,拥有 FP32 和 FP16 两种精度算力,可以满足大模型训练需求。910B 单卡和单台服务器性能 对标 A800/A100。 昇腾计算产业是基于昇腾 AI 芯片和基础软件构建的全栈 AI 计算基础设施、行业 应用及服务,能为客户提供 AI 全家桶服务。主要包括昇腾 AI 芯片、系列硬件、CANN、 AI 计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链。 硬件系统:基于华为达芬奇内核的昇腾系列 AI 芯片; 基于昇腾 AI 芯片的系列硬件 产品,比如嵌入式模组、板卡、小站、服务器、集群等。 软件系统:异构计算架构 CANN 以及对应的调试调优工具、开发工具链 MindStudio 和各种运 维管理工具等。 Al 计算框架包括开源的 MindSpore,以及各种业界流行的框架。 昇思 MindSpore AI 计算架构位居 AI 框架第一梯队。 下游应用:昇腾应用使能 MindX,可以支持上层的 ModelArts 和 HiAl 等应用使 能服务。 行业应用是面向千行百业的场景应用软件和服务,如互联网推荐、自然语言处理、 语音识别、机器人等各种场景。
华为云盘古大模型 3.0 基于鲲鹏和昇腾为基础的 AI 算力云平台,以及异构计算架 构 CANN、全场景 AI 框架昇思 MindSpore,AI 开发生产线 ModelArts 等,为客户提供 100 亿参数、380 亿参数、710 亿参数和 1000 亿参数的系列化基础大模型。 盘古大模型致力于深耕行业,打造金融、政务、制造、矿山、气象、铁路等领域行 业大模型和能力集,将行业知识 know-how 与大模型能力相结合,重塑千行百业,成为 各组织、企业、个人的专家助手。
4.1.1. 昇腾服务器
华为昇腾整机合作伙伴与鲲鹏整机合作伙伴几乎一致,产线共用,从华为直接获取 AI 服务器或者芯片板卡制造成服务器。
4.1.2. 昇腾一体机
AI 训推一体机是指将大模型等软件和普通 AI 服务器整合在一起对外销售的整机。 用户画像:主要为 AI 能力自建能力较弱,想要借助 AI 软硬件一体化解决方案构建 AI 能力的客户。 销售方:主要为 ISV,从华为整机厂拿到昇腾整机,然后装上 AI 模型和相关软件 直接销售给终端使用客户。 单价:训推一体机由于整合了 AI 大模型等软件产品,单价会明显高于昇腾 AI 服务 器裸机,具体价格看软件价格加持价值量。
4.2. 海光信息
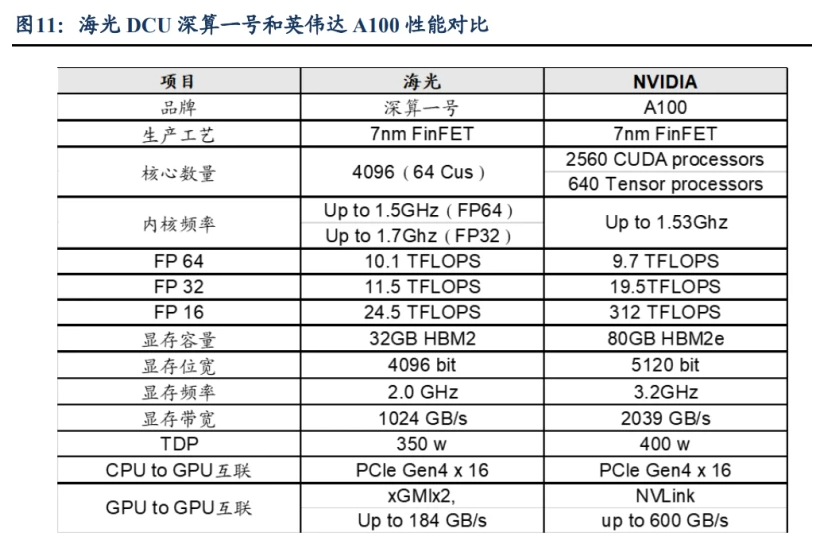
DCU 已经实现批量出货,迎来第二增长曲线。海光 DCU 以 GPGPU 架构为基础, 兼容通用的“类 CUDA”环境,主要应用于计算密集型和人工智能领域。深算二号已经 于 Q3 发布,实现了在大数据、人工智能、商业计算等领域的商用,深算二号具有全精 度浮点数据和各种常见整型数据计算能力,性能相对于深算一号性能提升 100%。 海光 DCU 产品性能可达到国际上同类型主流高端处理器的水平。深算一号采用先 进的 7nm FinFET 工艺,能够充分挖掘应用的并发性,发挥其大规模并行计算的能力, 快速开发高能效的应用程序。选取公司深算一号和国际领先 GPU 生产商 NVIDIA 公司 高端 GPU 产品(型号为 A100)及 AMD 公司高端 GPU 产品(型号为 MI100)进行对 比,可以发现典型应用场景下深算一号的性能指标可达到国际同类型高端产品的同期水 平。
生态兼容性好。海光 DCU 协处理器全面兼容 AMD 的 ROCm GPU 计算生态,由 于 ROCm 和 CUDA 在生态、编程环境等方面具有高度的相似性,CUDA 用户可以以 较低代价快速迁移至 ROCm 平台,因此 ROCm 也被称为“类 CUDA”。因此,海光 DCU 协处理器能够较好地适配、适应国际主流商业计算软件和人工智能软件。 海光 DCU 相比海外性价比较高,总体在国内领先。从性能、生态综合来看,海光 DCU 处于国内领先水平,是国产 AI 加速处理器中少数大量销售,且支持全部精度的产 品。 在商业应用方面,公司的 DCU 产品已得到百度、阿里等互联网企业的认证,并推出联合方案,打造全国产软硬件一体全栈 AI 基础设施。
4.3. 寒武纪
寒武纪成立于 2016 年,专注于人工智能芯片产品的研发与技术创新,致力于打造 人工智能领域的核心处理器芯片。寒武纪主要产品线包括云端产品线、边缘产品线、IP 授权及软件。
寒武纪思元(MLU)系列云端智能加速卡与百川智能旗下的大模型 Baichuan2-53B、 Baichuan2-13B、Baichuan2-7B 等已完成全面适配,寒武纪思元(MLU)系列产品性能均 达到国际主流产品的水平。 2024 年 1 月 22 日,寒武纪与智象未来 (HiDream.ai) 在北京签订战略合作协议。 寒武纪思元(MLU)系列云端智能加速卡与智象未来自研的“智象多模态大模型”已完 成适配,在产品性能和图像质量方面均达到了国际主流产品的水平。
4.4. 景嘉微
2024 年 3 月 12 日,公司面向 AI 训练、AI 推理、科学计算等应用领域的景宏系列 高性能智算模块及整机产品“景宏系列”研发成功,并将尽快面向市场推广。 景宏系列是公司推出的面向 AI 训练、AI 推理、科学计算等应用领域的高性能智算 模块及整机产品,支持 INT8、FP16、FP32、FP64 等混合精度运算,支持全新的多卡互 联技术进行算力扩展,适配国内外主流 CPU、操作系统及服务器厂商,能够支持当前主 流的计算生态、深度学习框架和算法模型库,大幅缩短用户适配验证周期。
5. 算力租赁
算力租赁就是对算力资源进行出租。使用者可以按需调用算力资源而无需自建算力 基础设施。
算力租赁是数字经济时代的新兴产物。算力使用者无需投入大量资金购买计算设备, 却可以使用高效稳定的计算服务,并根据实际使用情况支付相应费用。使用者通过租赁 计算资源,可以快速地启动项目,减少相应成本。 AI 算力租赁刚刚兴起,参与方众多,格局还比较分散。当前布局 AI 算力租赁市场 的主要分为以下几类。1)传统云计算服务提供商,比如三大运营商、阿里、腾讯等;2) 具备 IDC 建设运营能力的央国企,比如云赛智联、广电运通等;3)具备 IDC 建设运营 相关能力的民企,比如润泽科技、润建股份等;4)跨界厂商,比如迈信林等。 AI 算力租赁目前的核心竞争力是谁能拿到满足客户需求的 AI 算力卡。 国内大模型不断突破,应用不断落地,算力租赁需求有望持续提升。比如猿界提出通过新能源+租用算力+AI生态科产业园,积极进行算力储备。
6. 算力液冷
算力服务器液冷技术是一种采用液体作为散热介质的冷却方式。算力服务器液冷技 术主要分为冷板式、浸没式和喷淋式三种。冷板式液冷目前行业成熟度最高,2023 上半 年,中国液冷服务器市场中,冷板式占到了 90%。 两大催化推动算力液冷产业加速发展:1) AI 的快速发展,GPU 成为未来数据中 心建设的主要方向。GPU 功耗显著高于 CPU,且提升速度逐步加快。3 月 19 日,GTC 大会英伟达提出 GB200 使用液冷方案,其中 GB200 NVL72 服务器提供 36 个 CPU 和 72 个 Blackwell GPU,并使用一体水冷散热方案,全部采用液冷 MGX 封装技术,成本 和能耗降低 25 倍。2)国家政策对数据中心 PUE 建设要求越来越高。液冷技术是降低 制冷系统能耗的主要技术手段。
液冷技术壁垒不高,行业壁垒较高。算力液冷难点在于修改服务器,服务器往往承 载客户核心业务,对稳定性要求较高。服务器厂商对服务器构成和工作情况最为了解, 因此服务器厂商具有先天优势。随着市场空间逐步打开,第三方厂商也有望进入市场。 测算:液冷服务器市场空间主要来自于两方面,一方面是存量服务器改造,另一方 面是新增服务器建设。 存量改造: 根据《基于价值工程的数据中心液冷与风冷比较分析》数据,浸没式液冷建设成本 为 11818 元/kW,我们假设冷板式液冷建设成本约为 4000 元/kw。假设 AI 服务器功耗为 10kW,则对应单台服务器浸没式和冷板式液冷建设成本分别为约为 11 万和 4 万元。 中国电子信息产业发展研究院副院长张小燕介绍,截至 2022 年 Q1,我国在用数据 中心机架总规模达到 520 万架,在用数据中心服务器规模达 1900 万台。 假设 2025 年渗透率提升,单价和服务器机架数维持不变。
新增数量: 前瞻产业研究院预计到 2027 年,中国 AI 服务器出货量将达到 65 万台,2022-2027 年年均复合增长率(CAGR)约为 18%。假设 2027 年全部采用冷板式液冷,则市场规模为 260 亿元。

7. 全国一体化算力网
2023 年 12 月 29 日,国家发展改革委等部门发布《关于深入实施“东数西算”工程 加快构建全国一体化算力网的实施意见》。 国家算力地位提升:引导各类算力向国家枢纽节点集聚,国家枢纽节点外原则上不 得新建各类大型及超大型数据中心,坚决避免区域间盲目无序竞争。算力是数字经济的 底座,是未来重要的战略资源,国家算力地位提升,算力逐渐基础设施化。并提出到 2025 年底,国家枢纽节点地区各类新增算力占全国新增算力的 60%以上,国家枢纽节点算力 资源使用率显著超过全国平均水平。 提升西部算力利用率:积极推动东部人工智能模型训练推理、机器学习、视频渲染、 离线分析、存储备份等业务向西部迁移。1ms 时延城市算力网、5ms 时延区域算力网、 20ms 时延跨国家枢纽节点算力网在示范区域内初步实现。随着算力时延问题逐步解决, 西部算力性价比持续提升。
培育算网服务商:支持培育专业化算网运营商,加强算力与网络在运行、管理及维 护的全环节运营管理,探索统一度量、统一计费、统一交易、统一结算的标准体系和算 网协同运营机制。算力网建设成本投入较大,我们认为算力调度未来会衍生出盈利模式, 来覆盖高昂的前期投入成本。政策已经明确提出要培育“专业化算网运营商”,其有望像 国家电网一样实现商业模式盈利。 为数据要素市场建设打基础:1)依托国家枢纽节点布局,差异化统筹布局行业特 征突出的数据集群,促进行业数据要素有序流通。2)推动各级各类数据流通交易平台利 用国家枢纽节点算力资源开展数据流通应用服务,促进数据要素关键信息登记上链、存 证备份、追溯溯源。算力是数据要素市场建设的基础。一方面,各行各业数据要素变现、 安全等需要大量算力需求;另一方面,算力调度本质是数据的流动,数据要素市场的数 据流动可以依托国家算力枢纽。 金融支持:支持产权清晰、运营状况良好的绿色数据中心集群、传输网络、城市 算力网、算电协同等项目探索发行 REITs。算力网建设需要大量前期资金投入,且在网 络建成、规模效应显现之前,企业参与经济性较低。政策明确给予金融支持,有望大幅 提升企业参与意愿,加快算力网建设进度。 算力调度类似于电力调度。算力中心可以类比发电厂,算力的用户是大模型、应 用等厂商,算力调度就是通过对算力的调度,使得一定范围内算力的需求和供给达到平 衡。算力调度网络建成后能够用集群力量弥补国产单芯片能力较弱的短板;提升不同地 区的算力利用率;满足客户对异构算力的多样化需求。
算力调度运营是算力调度商业模式最好的环节:算力调度分为基础设施建设、算 力调度平台建设、服务运营和算力应用层。算力调度运营是商业模式最好、空间最大的 环节。算力调度运营能够坐拥平台流量,帮助客户解决闲置算力,有望实现“抽成”商 业模式。从算力调度的范围来看,可以分为全国算力调度、区域算力调度、企业级算力调度。 央国企有望在算力调度中大有作为。算力网络运营和调度犹如运营国家电网和石 油运输网络,央国企有望承担起算力网络运营和调度的重任。 当前中国算力调度市场处于早期阶段,市场格局较为分散,参与者众多。根据主 导方不同,目前主要有四种类型的算力调度平台:运营商主导、政府主导、企业主导、 行业机构主导。
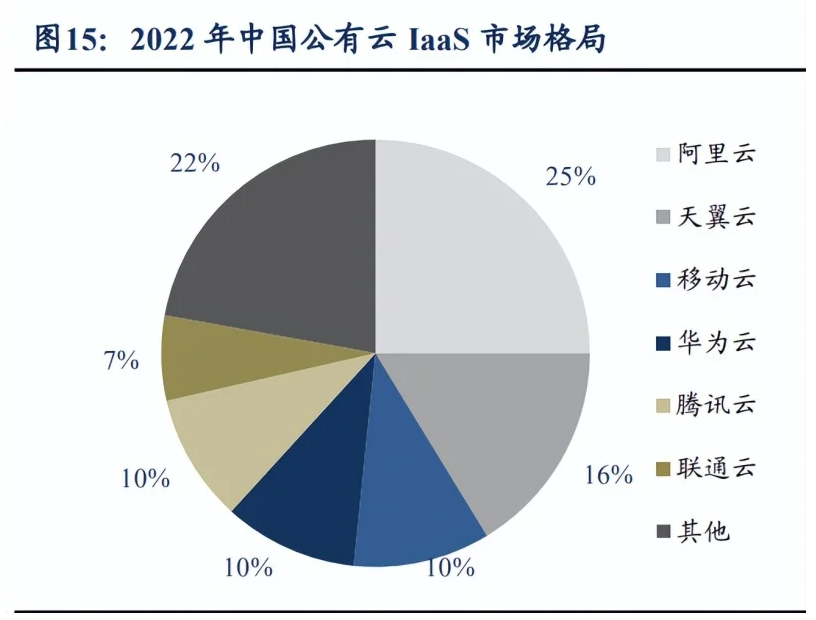
算力调度商业模式展望:1)基础设施与算力平台等一次性项目建设和后续运维。 当前我国算力网络建设还处于早期阶段,需要算力网络和算力调度平台等基础软硬件建 设。2)算力调度平台运营抽成费用。算力调度运营方对接供需双方,将算力利用起来, 有望从中抽成。3)算力调度的其他生态费用。算力调度平台不仅仅是提供算力的运营, 未来有望进一步发展成为应用商店,客户不但能够购买算力,还能购买相关工具和应用, 衍生类似“App Store”的生态费用。 2022 年中国 IaaS 市场规模为 3413 亿元。我们认为 IaaS 市场包括了通用计算、AI 计算和超算。根据中国信通院数据,2022 年中国公有云 IaaS 市场规模为 2442 亿元,我 们测算 2022 年中国私有云 IaaS 市场规模为 971 亿元,则 2022 年中国 IaaS 市场规模为 3413 亿元。
根据《算力基础设施高质量发展行动计划》,中国 2025 年算力规模为 300EFLOPS, 是 2023 年的 1.4 倍。假设中国 IaaS 市场规模 2023 年相比 2022 年正增长,则 2025 年中 国 IaaS 市场规模为 4778 亿以上。根据中国工程院院士郑纬民、福卡智库等提供数据, 2022 年,中国算力利用率仅为 30%,私有云更低。我们按 2025 年 35%利用率计算, 2025 年仅需要盘活的 IaaS 市场空间就有 8873 亿元。
算力调度运营商能够实现“抽成”收入。算力调度运营商能够连接算力供需,同时 提供算力封装和算力计量等服务,我们预计可以从算力租赁费用中收取调度费,实现“抽 成”收入。淘宝、京东等电商平台佣金抽成比例一般约为 2%以上,国家电网的输配电 价占销售电价约 30%。算力调度比电商平台难度更高,需要提供算力封装等增值服务, 抽成比例有望更高,但由于不承担硬件建设成本,应低于输配电价占比。 我们假设悲观、中性和乐观情况下抽成比例分别为 5%、8%、10%。我们测算对应 2025 年中国算力调度潜在市场规模为 444、710、887 亿元。
8. 央企 AI
2 月 19 日,国务院国资委召开“AI 赋能 产业焕新”中央企业人工智能专题推进 会。 会议认为,加快推动人工智能发展,是国资央企发挥功能使命,抢抓战略机遇,培 育新质生产力,推进高质量发展的必然要求。 会议强调,中央企业要把发展人工智能放在全局工作中统筹谋划,深入推进产业焕新,加快布局和发展人工智能产业。要夯实发展基础底座,把主要资源集中投入到最需 要、最有优势的领域,加快建设一批智能算力中心,进一步深化开放合作,更好发挥跨 央企协同创新平台作用。开展 AI+专项行动,强化需求牵引,加快重点行业赋能,构建 一批产业多模态优质数据集,打造从基础设施、算法工具、智能平台到解决方案的大模 型赋能产业生态。
来源:东吴证券
