


DeepSeek R1 震撼登场,引发市场巨震

当地时间 1 月 27 日,美国股市遭遇了一场剧烈的震荡,科技板块成为重灾区。这场动荡的背后,是一家来自中国的人工智能初创公司 ——DeepSeek。其发布的最新模型 R1,如同一颗重磅炸弹,在全球 AI 领域掀起了惊涛骇浪,尤其是让美国芯片巨头英伟达(NVIDIA)的股价暴跌约 17%,市值一夜之间蒸发近 6000 亿美元 ,创下华尔街股票市值单日最大跌幅的纪录。与此同时,博通公司股价下跌 17%,超威半导体公司(AMD)股价下跌 6%,微软股价下跌 2%,人工智能领域的衍生品,如电力供应商也未能幸免,美国联合能源公司股价下跌 21%,Vistra 的股价下跌 29%。
1 月 20 日,DeepSeek 正式发布推理大模型 DeepSeek-R1,这是一个开源推理模型,却有着惊人的表现。据报道,它在数学、代码、自然语言推理等多项测试中的表现优于 OpenAI 等美国公司的最佳模型,而其自报的培训成本不到 600 万美元,与硅谷公司为构建人工智能模型所花费的数十亿美元相比,简直是九牛一毛。这样的成本优势和卓越性能,瞬间吸引了全球的目光。1 月 27 日早间,DeepSeek 应用更是登顶苹果中国地区和美国地区应用商店免费 APP 下载排行榜,在美区下载榜上超越了 ChatGPT,足见其受欢迎程度。
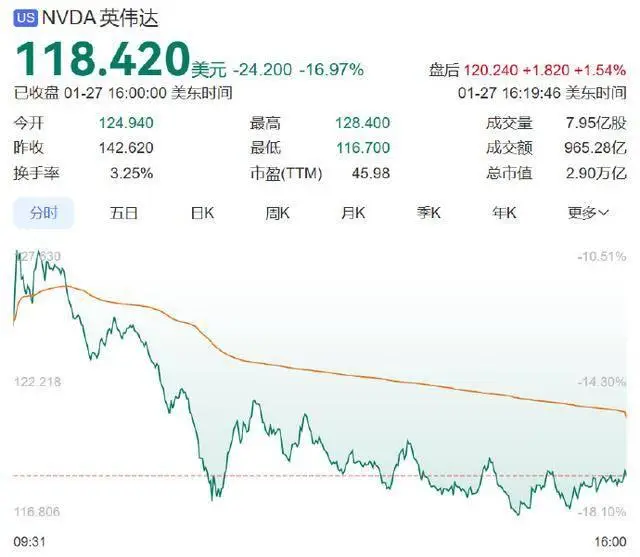
英伟达正面回应,肯定技术进步
在股价暴跌的阴霾下,英伟达却展现出了大度与远见。1 月 28 日,英伟达发言人向 CNBC 表示:“DeepSeek 是一项出色的 AI 进步,也是测试时间扩展(Test Time Scaling,TTS)的完美范例。DeepSeek 的工作展示了如何使用该技术创建新模型,利用广泛使用的模型和完全符合出口管制的计算。” 英伟达认为,DeepSeek 的突破并非对自身的威胁,反而将为其图形处理单元(GPU)创造更多的工作机会。推理需要大量 NVIDIA GPU 和高性能网络,这是不争的事实。随着 AI 技术的不断发展,推理过程对于计算能力的需求只会与日俱增,而英伟达作为 GPU 领域的佼佼者,有望从中受益。
此外,英伟达还特别指出,DeepSeek 使用的 GPU 完全符合出口要求,这一说法与 Scale AI 首席执行官 Alexandr Wang 上周在 CNBC 上的评论形成了鲜明的矛盾。后者曾认为 DeepSeek 使用的是中国禁止使用的 Nvidia GPU 型号,但 DeepSeek 方面表示,他们使用的是专为中国市场设计的 Nvidia GPU 的特殊版本 。这一争议的背后,凸显了国际科技合作与竞争中,对于技术合规性和透明度的高度关注。
R1 模型实力剖析,性能超越预期
DeepSeek R1 模型的惊艳表现,是其在技术创新上的厚积薄发。在数学能力基准测试中,R1 模型取得了 77.5% 的准确率,这一成绩足以让许多同类模型望尘莫及。在面对复杂的数学问题时,它能够迅速理清思路,运用强大的推理能力给出准确的解答。在 Codeforces 编程评测中,它获得了 2441 分,超过了 96.3% 的参赛者 ,这意味着它在编程领域的能力已经达到了顶尖水平。无论是代码的编写、调试还是优化,R1 模型都能应对自如,为开发者提供高效的帮助。
与 OpenAI 的顶尖模型 o1 相比,R1 模型在多个维度上展现出了独特的优势。在推理速度上,R1 模型更快,能够在更短的时间内给出答案,大大提高了工作效率。在成本方面,R1 模型更是具有压倒性的优势,其 API 调用成本仅为 o1 的几十分之一,这使得更多的企业和开发者能够负担得起,从而推动 AI 技术的更广泛应用。在一些复杂的任务中,R1 模型的表现也毫不逊色,甚至在某些特定场景下超越了 o1 模型,展现出了强大的适应性和灵活性。
成本优势显著,挑战传统投资模式
DeepSeek R1 模型的低成本,无疑是对传统 AI 投资模式的一次巨大挑战。长期以来,微软、谷歌、Meta 等科技巨头在 AI 领域投入了巨额资金,构建庞大的 AI 基础设施。微软计划在 2025 年投入 800 亿美元用于人工智能基础设施建设,Meta 首席执行官马克・扎克伯格也表示,作为其人工智能战略的一部分,2025 年将投资 600 亿至 650 亿美元 。这些巨额投入,旨在通过大规模的计算和数据处理,开发出更强大的人工智能系统。
然而,DeepSeek R1 模型的出现,让人们开始反思这种投资模式的必要性。如果仅需不到 600 万美元的成本,就能实现甚至超越这些巨额投资所带来的成果,那么过去的数十亿美元投资是否真的物有所值?美国银行证券分析师贾斯汀・波斯特在报告中指出:“如果模型训练成本被证明可以大幅降低,我们预计,使用云 AI 服务的广告、旅游和其他消费应用公司将在短期内获得成本效益,而长期来看,超大规模 AI 相关的收入和成本可能会更低。” 这意味着,R1 模型的低成本优势,不仅可能改变 AI 技术的开发模式,还将对整个 AI 产业的经济结构产生深远影响。
对于那些依赖云 AI 服务的企业来说,R1 模型带来了新的希望。它们可以在不投入大量资金的情况下,享受到高性能的 AI 服务,降低运营成本,提高市场竞争力。从长远来看,这可能会促使 AI 技术更加普及,推动各行各业的数字化转型。而对于那些在 AI 领域投入了巨额资金的科技巨头来说,R1 模型的出现无疑是一种压力。他们需要重新审视自己的 AI 战略,思考如何在降低成本的同时,保持技术的领先地位。
出口管制争议,真相浮出水面
在这场 AI 风暴中,DeepSeek 使用的 GPU 是否符合出口管制规定成为了焦点之一。Scale AI 首席执行官 Alexandr Wang 曾认为 DeepSeek 使用的是中国禁止使用的 Nvidia GPU 型号,这一言论引发了广泛的关注和猜测。然而,英伟达的声明却为这一争议画上了一个明确的句号。英伟达表示,DeepSeek 使用的 GPU 完全符合出口要求,这无疑是对市场疑虑的有力回应。
DeepSeek 方面也强调,他们使用的是专为中国市场设计的 Nvidia GPU 的特殊版本 。这一特殊版本的 GPU,既满足了 DeepSeek 在模型训练和推理过程中对计算能力的需求,又确保了其在合规的框架内运行。这一事实不仅体现了 DeepSeek 在技术选型上的谨慎和合规意识,也展示了其在复杂的国际科技环境中,通过合理的技术手段实现创新突破的能力。
出口管制问题的背后,是国际科技竞争的大格局。在 AI 技术成为全球战略竞争焦点的今天,技术的合规性和透明度显得尤为重要。英伟达对 DeepSeek 使用 GPU 合规性的确认,不仅有助于消除市场的误解,也为国际科技合作树立了一个积极的范例。它表明,即使在竞争激烈的环境下,科技企业仍然可以通过合法、合规的方式,实现技术的共享与创新,推动 AI 技术的全球发展。
缩放定律新解,AI 发展新方向
在 AI 的发展历程中,“缩放定律” 曾是指引行业前进的重要灯塔。2020 年,OpenAI 研究人员提出的这一概念,认为通过大大扩展构建新模型所需的计算量和数据量,就能开发出更好的人工智能系统 。这意味着,企业想要在 AI 领域取得突破,就必须不断投入巨额资金,扩大计算资源和数据规模。微软、谷歌、Meta 等科技巨头的巨额投资,正是基于对这一定律的深信不疑。
然而,DeepSeek R1 模型的出现,为缩放定律赋予了新的内涵。它通过测试时间扩展(TTS)这一创新技术,打破了传统缩放定律中对计算量和数据量的单一依赖。在推理阶段,R1 模型合理地配置计算资源,花费更多时间进行深度推理,从而在不依赖大规模计算资源的情况下,实现了性能的大幅提升。这就像是在一场比赛中,R1 模型没有选择一味地加大马力,而是通过优化驾驶策略,以更高效的方式冲过了终点线。
这种新的思路,为 AI 的发展开辟了一条新的道路。它让人们看到,AI 的进步并非只有一条依赖巨额投资的 “华山之路”。在资源有限的情况下,通过技术创新和算法优化,同样可以实现 AI 性能的飞跃。这对于那些无法承担巨额投资的中小企业来说,无疑是一个巨大的鼓舞。他们可以在这条新的赛道上,凭借创新的思维和技术,与科技巨头们展开公平的竞争。
从更宏观的角度来看,DeepSeek R1 模型的成功,预示着 AI 发展将进入一个更加多元化的时代。未来,AI 技术的发展可能不再仅仅依赖于大规模的计算资源和数据,而是会更加注重技术的创新和应用场景的挖掘。在这个过程中,不同规模的企业都将有机会发挥自己的优势,推动 AI 技术在各个领域的广泛应用。无论是医疗、教育、金融,还是制造业、服务业,AI 都将以更加高效、低成本的方式,为人们的生活和工作带来更多的便利和创新。
